by R.I. Pienaar | Dec 5, 2007 | Front Page
Yesterday while trying to get a i386 DomU going on my x86_64 Xen server I ran into some hassles with ‘No space left on device’ errors.
Anyone who sees that would immediately go for the df command, but it would be futile in this instance.
What happens is that the xenstore – where it stores meta files state of the running VMs – gets corrupt,
You can try and run ‘xenstore-control check’ it will also give some b/s answer kind of suggesting all is well, it’s not, check /var/log/messages and you’ll see stuff like:
xenstored: corruption detected by connection 0: \
err No such file or directory: Write failed
xenstored: clean_store: '/local/domain/0/backend/vbd/16/51712/sectors' is orphaned!
At this point you’re pretty much screwed, try and reboot and xend won’t even run, no VM’s will start.
Fixing it is pretty easy in the end once you’ve done tons of Googling and found the 2 year old bug in the Xen bugtracker about this exact problem – complete with the xen guys trying to close it in a routine ‘cleanup of tickets’ rather than actually fixing the bug.
First, shut down all things Xen, if you can even boot from a non Xen kernel. Once you’re sure its all down just delete /var/lib/xenstored/tdb* and reboot, it should all be fine after that.
You must be sure you don’t have xenstored running while doing this, else it will write its in-memory corrupted state back to disk when you reboot and it will look like your fix didn’t work.
by R.I. Pienaar | Dec 2, 2007 | Front Page
The CentOS team today released CentOS 5.1. This is good news there has been a ton of bug fixes upstream.
It is still trickling out to a few mirrors so should be available everywhere soon, I updated my 2 development servers using:
yum –disablerepo=\* –enablerepo=base –enablerepo=updates update
And so far it is all good, be aware that there seems to be a small issue with /etc/redhat-release still showing things as it was with 5.0, but this will probably be fixed soon as there has already been mentions of this on the forums.
As always, read the release notes before you upgrade as there are some outstanding issues you should know about.
Well done, the Wiki has also recently had a layout upgrade and it is all starting to look much more professional than before.
by R.I. Pienaar | Dec 2, 2007 | Front Page
I keep a pretty close eye on my email volumes as I own a little anti spam company – you point your MX to me and I’ll deliver a clean set of email to your server, nothing too complex.
A while ago while looking at my overall flow of email I noted this drop:
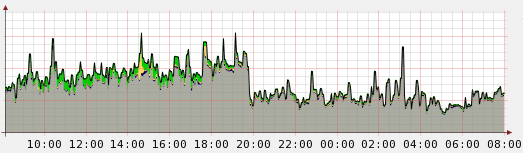
I thought it might be an anomaly or just a short interruption but it’s kept at this limit for a few weeks now. The only thing I can imagine is that some big botnet got shut down or very prolific spammer packed up shop as my average rate of connections have halved as in the graph.
There was a well publicized story in the news recently about Google also seeing a drop in spam their’s doesn’t seem to suggest a sudden drop but my stats and the news from them certainly makes me feel better.
by R.I. Pienaar | Nov 25, 2007 | Usefull Things
I played with heartbeat a year or so ago and while it was ok, I was not convinced it was 100% there yet, it lacked monitoring capabilities of resources it managed which was a major drawback in my mind.
I again had a need for a cluster recently so had another look. Since the previous time they’ve released Heartbeat version 2 which has a full resource manager like you’ll find in more mature systems.
The only time I’ve previously used a cluster system extensively was on Windows 2003 Enterprise with MS SQL Server Enterprise, the setup then was a active-passive SQL cluster with shared fibre storage. The windows cluster services works quite well, have a solid GUI and supports many nodes in a cluster.
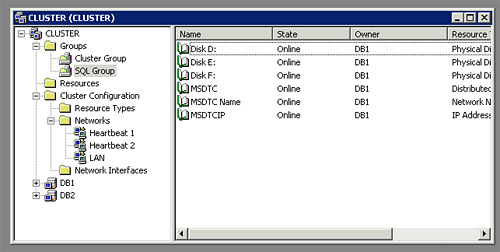
I wouldn’t yet compare Heartbeat to commercial offerings, technically the Cluster Resource Manager introduced in version 2 is a massive step forward but configuration can be a real nightmare.
The documentation is very thin on the ground and configuration has to be done through XML files. There is a disturbing trend these days for people to think XML is an acceptable form of configuration from a human point of view but it really is not. Worse is the DTD for the XML format is the definitive source for configuration reference, as their WIKI states:
It was out of date and didn’t take into account the fact that not everyone is on the same version. Instead, you should refer to crm.dtd on your system (which is always appropriate to your version).
Heartbeat does provide a GUI but I found it immature, inconsistent and often had error messages pop up with no contents in them other than an ‘OK’ button. It also lacked some features, while evaluating it I decided if I had to rely on the GUI in any way as it stands today I would not use Heartbeat for my cluster as it would invalidate any high availability hopes I had. It is useful though to monitor and visualise your cluster, especially if you have a lot of groups.
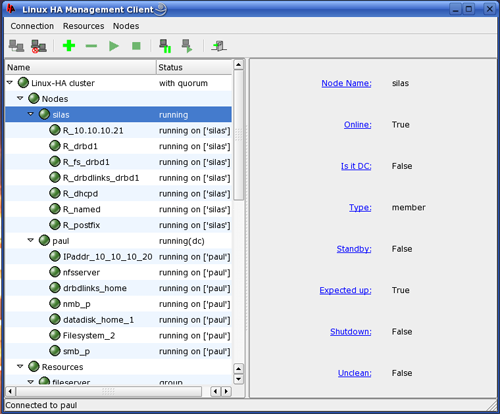
Once I figured out the correct XML formats to do what I wanted and learned the command line tools and provided my own documentation for these I eventually got a full 2 node cluster going managing currently 5 resources with more to follow.
My main goal with this project was to manage HAProxy on the cluster not because HAProxy is in any way unstable but because I find it difficult to do maintenance with just one machine for it and as I adopt HAProxy more the hardware would be an unacceptable single point of failure.
Heartbeat lets you manage resources using several type of scripts, the best one to use would be the new OCF standard scripts which is designed specifically for managing cluster resources but it’s an emerging format so not a lot of scripts exist for it today. Heartbeat also support using standard /etc/init.d/ style rc scripts with the caveat that they have to be 100% LSB compliant. You’d think at least the scripts that Red Hat provide are LSB compliant but you’d be wrong, I had to fiddle with almost each one I wanted to use which is not optimal because I hate editing non-config files delivered with RPM and I think its very poor of RedHat who has been making a point of telling anyone who would listen that they’re completely LSB compliant.
I would also have liked to build a HA NFS server but unfortunately Heartbeat version 2 and DRBD version 8 does not yet play nicely, so that is a project for some other time.
My conclusions on Heartbeat then is that it is a good solid project especially with version 2, I think in a year or so once documentation etc had a chance to mature it would be a good choice for almost anyone, for now though it is unfortunately out of reach for the average guys.
by R.I. Pienaar | Nov 15, 2007 | Front Page
I am quite a big fan of CentOS, I run all my own systems on it and its my first recommendation for clients.
I’ve been using Red Hat since their Halloween release 31 October 1994. The major thing you notice about it is that it stays consistent and sticks to standards – usually existing ones without trying to make its own.
Consistency is really important in my mind from an Operating System, you do not want to redesign your own systems just because you go up a point release or even a major release. Red Hat more than certain other popular Linux Distribution has been providing this for years now.
CentOS gets the benefit of all of this plus provides you with a reasonably easy upgrade path to Red Hat should your investors for example require this, it maintains binary compatibility with Red Hat proper so you can rest assured that should the need arise to upgrade to a supported distribution you at least won’t need to redevelop your own code.
Why anyone would pay Red Hat support is another matter, I cannot remember a single instance of being satisfied with their support in the various places I’ve used them.
Anyway, 62976 processor core CentOS machines? Sun just announced their Constellation System HPC cluster based on their new blades as a backbone. From a searchdatacenter.com article the following:
The Sun Constellation CentOS Linux Cluster, named Ranger, will have 3,936 nodes, 123 terabytes of memory and 62,976 processor cores from AMD Opteron quad-core processors. The system is specifically designed to support very large science and engineering computing, according to TACC.
