by R.I. Pienaar | Mar 21, 2017 | Uncategorized
The old MCollective protocols are now ancient and was quite Ruby slanted – full of Symbols and used YAML and quite language specific – in Choria I’d like to support other Programming Languages, REST gateways and so forth, so a rethink was needed.
I’ll look at the basic transport protocol used by the Choria NATS connector, usually it’s quite unusual to speak of Network Protocols when dealing with messages on a broker but really for MCollective it is exactly that – a Network Protocol.
The messages need enough information for strong AAA, they need to have an agreed on security structure and within them live things like RPC requests. So a formal specification is needed which is exactly what a Protocol is.
While creating Choria the entire protocol stack has been redesigned on every level except the core MCollective messages – Choria maintains a small compatibility layer to make things work. To really achieve my goal I’d need to downgrade MCollective to pure JSON data at which point multi language interop should be possible and easy.
Networks are Onions
Network protocols tend to come in layers, one protocol within another within another. The nearer you go to the transport the more generic it gets. This is true for HTTP within TCP within IP within Ethernet and likewise it’s true for MCollective.
Just like for TCP/IP and HTTP+FTP one MCollective network can carry many protocols like the RPC one, a typical MCollective install uses 2 protocols at this inner most layer. You can even make your own, the entire RPC system is a plugin!
( middleware protocol
( transport packet that travels over the middleware
( security plugin internal representation
( mcollective core representation that becomes M::Message
( MCollective Core Message )
( RPC Request, RPC Reply )
( Other Protocols, .... )
)
)
)
)
) |
( middleware protocol
( transport packet that travels over the middleware
( security plugin internal representation
( mcollective core representation that becomes M::Message
( MCollective Core Message )
( RPC Request, RPC Reply )
( Other Protocols, .... )
)
)
)
)
)
Here you can see when you do mco rpc puppet status you’ll be creating a RPC Request wrapped in a MCollective Message, wrapped in a structure the Security Plugin dictates, wrapped in a structure the Connector Plugin dictates and from there to your middleware like NATS.
Today I’ll look at the Transport Packet since that is where Network Federation lives which I spoke about yesterday.
Transport Layer
The Transport Layer packets are unauthenticated and unsigned, for MCollective security happens in the packet carried within the transport so this is fine. It’s not inconceivable that a Federation might only want to route signed messages and it’s quite easy to add later if needed.
Of course the NATS daemons will only accept TLS connections from certificates signed by the CA so these network packets are encrypted and access to the transport medium is restricted, but the JSON data you’ll see below is sent as is.
In all the messages shown below you’ll see a seen-by header, this is a feature of the NATS Connector Plugin that records the connected NATS broker, we’ll soon expose this information to MCollective API clients so we can make a traceroute tool for Federations. This header is optional and off by default though.
I’ll show messages in Ruby format here but it’s all JSON on the wire.
Message Targets
First it’s worth knowing where things are sent on the NATS clusters. The targets used by the NATS connector is pretty simple stuff, there will no doubt be scope for improvement once I look to support NATS Streaming but for now this is adequate.
- Broadcast Request for agent puppet in the mycorp sub collective – mycorp.broadcast.agent.puppet
- Directed Request to a node for any agent in the mycorp sub collective – mycorp.node.node1.example.net
- Reply to a node identity dev1.example.net with pid 9999 and a message sequence of 10 – mycorp.reply.node1.example.net.9999.10
As the Federation Brokers are independent of Sub Collectives they are not prefixed with any collective specific token:
- Requests from a Federation Client to a Federation Broker Cluster called production – choria.federation.production.federation queue group production_federation
- Replies from the Collective to a Federation Broker Cluster called production – choria.federation.production.collective queue group production_collective
-
production cluster Federation Broker Instances publishes statistics – choria.federation.production.stats
These names are designed so that in smaller setups or in development you could use a single NATS cluster with Federation Brokers between standalone collectives. Not really a recommended thing but it helps in development.
Unfederated Messages
Your basic Unfederated Message is pretty simple:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => ["dev1.example.net", "nats1.example.net"],
"reply-to" => "mcollective.reply.dev1.example.net.999999.0",
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => ["dev1.example.net", "nats1.example.net"],
"reply-to" => "mcollective.reply.dev1.example.net.999999.0",
}
}
- it’s is a discovery request within the sub collective mcollective and would be published to mcollective.broadcast.agent.discovery.
- it is sent from a machine identifying as dev1.example.net
- we know it’s traveled via a NATS broker called nats1.example.net.
- responses to this message needs to travel via NATS using the target mcollective.reply.dev1.example.net.999999.0.
The data is completely unstructured as far as this message is concerned it just needs to be some text, so base64 encoded is common. All the transport care for is getting this data to its destination with metadata attached, it does not care what’s in the data.
The reply to this message is almost identical:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => ["dev1.example.net", "nats1.example.net", "dev2.example.net", "nats2.example.net"],
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => ["dev1.example.net", "nats1.example.net", "dev2.example.net", "nats2.example.net"],
}
}
This reply will travel via mcollective.reply.dev1.example.net.999999.0, we know that the node dev2.example.net is connected to nats2.example.net.
We can create a full traceroute like output with this which would show dev1.example.net -> nats1.example.net -> nats2.example.net -> dev2.example.net
Federated Messages
Federation is possible because MCollective will just store whatever Headers are in the message and put them back on the way out in any new replies. Given this we can embed all the federation metadata and this metadata travels along with each individual message – so the Federation Brokers can be entirely stateless, all the needed state lives with the messages.
With Federation Brokers being clusters this means your message request might flow over a cluster member a but the reply can come via b – and if it’s a stream of replies they will be load balanced by the members. The Federation Broker Instances do not need something like Consul or shared store since all the data needed is in the messages.
Lets look at the same Request as earlier if the client was configured to belong to a Federation with a network called production as one of its members. It’s identical to before except the federation structure was added:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => ["dev1.example.net", "nats1.fed.example.net"],
"reply-to" => "mcollective.reply.dev1.example.net.999999.0",
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"target" => ["mcollective.broadcast.agent.discovery"]
}
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => ["dev1.example.net", "nats1.fed.example.net"],
"reply-to" => "mcollective.reply.dev1.example.net.999999.0",
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"target" => ["mcollective.broadcast.agent.discovery"]
}
}
}
- it’s is a discovery request within the sub collective mcollective and would be published via a Federation Broker Cluster called production via NATS choria.federation.production.federation.
- it is sent from a machine identifying as dev1.example.net
- it’s traveled via a NATS broker called nats1.fed.example.net.
- responses to this message needs to travel via NATS using the target mcollective.reply.dev1.example.net.999999.0.
- it’s federated and the client wants the Federation Broker to deliver it to it’s connected Member Collective on mcollective.broadcast.agent.discovery
The Federation Broker receives this and creates a new message that it publishes on it’s Member Collective:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net"
],
"reply-to" => "choria.federation.production.collective",
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"reply-to" => "mcollective.reply.dev1.example.net.999999.0"
}
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev1.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net"
],
"reply-to" => "choria.federation.production.collective",
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"reply-to" => "mcollective.reply.dev1.example.net.999999.0"
}
}
}
This is the same message as above, the Federation Broker recorded itself and it’s connected NATS server and produced a message, but in this message it intercepts the replies and tell the nodes to send them to choria.federation.production.collective and it records the original reply destination in the federation header.
A node that replies produce a reply, again this is very similar to the earlier reply except the federation header is coming back exactly as it was sent:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net",
"dev2.example.net",
"nats2.prod.example.net"
],
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"reply-to" => "mcollective.reply.dev1.example.net.999999.0"
}
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net",
"dev2.example.net",
"nats2.prod.example.net"
],
"federation" => {
"req" => "68b329da9893e34099c7d8ad5cb9c940",
"reply-to" => "mcollective.reply.dev1.example.net.999999.0"
}
}
}
We know this node was connected to nats1.prod.example.net and you can see the Federation Broker would know how to publish this to the client – the reply-to is exactly what the Client initially requested, so it creates:
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net",
"dev2.example.net",
"nats2.prod.example.net",
"nats3.prod.example.net",
"fedbroker_production_b",
"nats3.fed.example.net"
],
}
} |
{
"data" => "... any text ...",
"headers" => {
"mc_sender" => "dev2.example.net",
"seen-by" => [
"dev1.example.net",
"nats1.fed.example.net",
"nats2.fed.example.net",
"fedbroker_production_a",
"nats1.prod.example.net",
"dev2.example.net",
"nats2.prod.example.net",
"nats3.prod.example.net",
"fedbroker_production_b",
"nats3.fed.example.net"
],
}
}
Which gets published to mcollective.reply.dev1.example.net.999999.0.
Route Records
You noticed above there’s a seen-by header, this is something entirely new and never before done in MCollective – and entirely optional and off by default. I anticipate you’d want to run with this off most of the time once your setup is done, it’s a debugging aid.
As NATS is a full mesh your message probably only goes one hop within the Mesh. So if you record the connected server you publish into and the connected server your message entered it’s destination from you have a full route recorded.
The Federation Broker logs and MCollective Client and Server logs all include the message ID so you can do a full trace in message packets and logs.
There’s a PR against MCollective to expose this header to the client code so I will add something like mco federation trace some.node.example.net which would send a round trip to that node and tell you exactly how the packet travelled. This should help a lot in debugging your setups as they will now become quite complex.
The structure here is kind of meh and I will probably improve on it once the PR in MCollective lands and I can see what is the minimum needed to do a full trace.
By default I’ll probably record the identities of the MCollective bits when Federated and not at all when not Federated. But if you enable the setting to record the full route it will produce a record of MCollective bits and the NATS nodes involved.
In the end though from the Federation example we can infer a network like this:
Federation NATS Cluster
- Federation Broker production_a -> nats2.fed.example.net
- Federation Broker production_b -> nats3.fed.example.net
- Client dev1.example.net -> nats1.fed.example.net
Production NATS Cluster:
- Federation Broker production_a -> nats1.prod.example.net
- Federation Broker production_b -> nats3.prod.example.net
- Server dev2.example.net -> nats2.prod.example.net
We don’t know the details of all the individual NATS nodes that makes up the entire NATS mesh but this is good enough.
Of course this sample is the pathological case where nothing is connected to the same NATS instances anywhere. In my tests with a setup like this the overhead added across 10 000 round trips against 3 nodes – so 30 000 replies through 2 x Federation Brokers – was only 2 seconds, I couldn’t reliably measure a per message overhead as it was just too small.
The NATS gem do expose the details of the full mesh though since NATS will announce it’s cluster members to clients, I might do something with that not sure. Either way, auto generated network maps should be totally possible.
Conclusion
So this is how Network Federation works in Choria. It’s particularly nice that I was able to do this without needing any state on the cluster thanks to past self making good design decisions in MCollective.
Once the seen-by thing is figured out I’ll publish JSON Schemas for these messages and declare protocol versions.
I can probably make future posts about the other message formats but they’re a bit nasty as MCollective itself is not yet JSON safe, the plan is it would become JSON safe one day and the whole thing will become a lot more elegant. If someone pings me for this I’ll post it otherwise I’ll probably stop here.
by R.I. Pienaar | Mar 20, 2017 | Uncategorized
Running large or distributed MCollective networks have always been a pain. As much as Middleware is an enabler it starts actively working against you as you grow and as latency increases, this is felt especially when you have geographically distributed networks.
Federation has been discussed often in the past but nothing ever happened, NATS ended up forcing my hand because it only supports a full mesh mode. Something that would not be suitable for a globe spanning network.
Overview
I spent the last week or two building in Federation first into the Choria network protocol and later added a Federation Broker. Federation can be used to connect entirely separate collectives together into one from the perspective of a client.
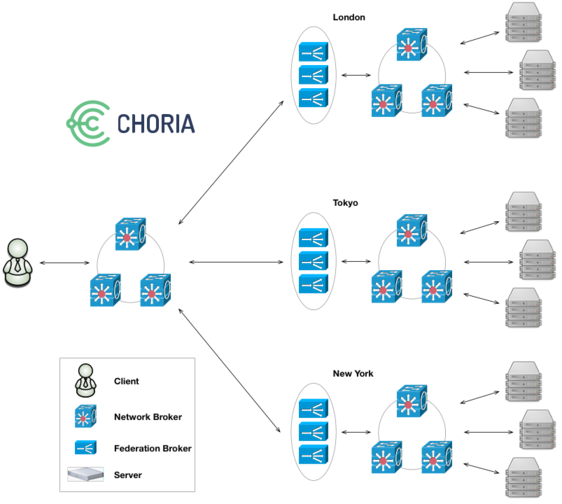
Here we can see a distributed Federation of Collectives. Effectively London, Tokyo and New York are entirely standalone collectives. They are smaller, they have their own middleware infrastructure, they even function just like a normal collective and can have clients communicating with those isolated collectives like always.
I set up 5 node NATS meshes in every region. We then add a Federation Broker cluster that provide bridging services to a central Federation network. I’d suggest running the Federation Broker Cluster one instance on each of your NATS nodes, but you can run as many as you like.
Correctly configured Clients that connect to the central Federation network will interact with all the isolated collectives as if they are one. All current MCollective features keep working and Sub Collectives can span the entire Federation.
Impact
There are obvious advantages in large networks – instead of one giant 100 000 node middleware you now need to built 10 x 10 000 node networks, something that is a lot easier to do. With NATS, it’s more or less trivial.
Not so obvious is how this scales wrt MCollective. MCollective has a mode called Direct Addressing where the client would need to create 1 message for every node targeted in the request. Generally very large requests are discouraged so it works ok.
These requests being made on the client ends up having to travel individually all across the globe and this is where it starts to hurt.
With Federation the client will divide the task of producing these per client messages into groups of 200 and pass the request to the Federation Broker Cluster. The cluster will then, in a load shared fashion, do the work for the client.
Since the Federation Broker tends to be near the individual Collectives this yields a massive reduction in client work and network traffic. The Federation Broker Instances are entirely state free so you can run as many as you like and they will share the workload more or less evenly across them.
$ mco federation observe --cluster production
Federation Broker: production
Federation
Totals:
Received: 1024 Sent: 12288
Instances:
1: Received: 533 (52.1%) Sent: 6192 (50.4%)
2: Received: 491 (47.9%) Sent: 6096 (49.6%) |
$ mco federation observe --cluster production
Federation Broker: production
Federation
Totals:
Received: 1024 Sent: 12288
Instances:
1: Received: 533 (52.1%) Sent: 6192 (50.4%)
2: Received: 491 (47.9%) Sent: 6096 (49.6%)
Above you can see the client offloading the work onto a Federation Broker with 2 cluster members. The client sent 1024 messages but the broker sent 12288 messages on the clients behalf. The 2 instances does a reasonable job of sharing the load of creating and federating the messages across them.
In my tests against large collectives this speeds up the request significantly and greatly reduce the client load.
In the simple broadcast case there is no speed up, but when doing 10 000 requests in a loop the overhead of Federation was about 2 seconds over the 10 000 requests – so hardly noticeable.
Future Direction
The Choria protocol supports Federation in a way that is not tied to its specific Federation Broker implementation. The basic POC Federation Broker was around 200 lines so not really a great challenge to write.
I imagine in time we might see a few options here:
- You can use different CAs in various places in your Federated network. The Federation Broker using Choria Security privileged certificates can provide user id mapping and rewriting between the Collectives
- If you want to build a SaaS management services ontop of Choria a Federated network makes a really safe way to reach into managed networks without exposing the collectives to each other in any way. A client in one member Collective cannot use the Federation Brokers to access another Collective.
- Custom RBAC and Auditing schemes can be built at the Federation Broker layer where the requests can be introspected and only ones matching policy are passed to the managed Collective
- Federation is tailor made to provide Protocol translation. Different protocol Collectives can be bridged together. An older MCollective SSL based collective can be reached from a Choria collective via a Federation Broker providing translation capabilities. Ditto a Websocket interface to Collectives can be a Federation Broker listening on Websocket while speaking NATS on the other end.
The security implications are huge, isolated collectives with isolated CAs and unique user Auditing, Authorization and Authentication needs bridged together via a custom RBAC layer, one that is horizontally scalable and stateless is quite a big deal.
Protocol translation is equally massive, as I move towards looking at ways to fork MCollective, given the lack of cooperation from Puppet Inc, this gives me a very solid way forward to not throw away peoples investment in older MCollective while wishing to find a way to move forward.
Availability
This will be released in version 0.0.25 of the Choria module which should be sometime this week. I’ve published pre-release docs already. Expect it to be deployable with very little effort via Puppet, given a good DNS setup it needs almost no configuration at all.
I’ll make a follow up post that explores the network protocol that made this possible to build with zero stored state in the Federation Broker Instances – a major achievement in my book.
UPDATE: All the gory protocol details are in a follow up post Choria Network Protocols – Transport.
by R.I. Pienaar | Feb 12, 2017 | Code
Recently at Config Management Camp I’ve had many discussions about Orchestration, Playbooks and Choria, I thought it’s time for another update on it’s status.
I am nearing version 1.0.0, there are a few things to deal with but it’s getting close. Foremost I wanted to get the project it’s own space on all the various locations like GitHub, Forge, etc.
Inevitably this means getting a logo, it’s been a bit of a slog but after working through loads of feedback on Twitter and offers for assistance from various companies I decided to go to a private designer called Isaac Durazo and the outcome can be seen below:


The process of getting the logo was quite interesting and I am really pleased with the outcome, I’ll blog about that separately.
Other than the logo the project now has it’s own GitHub organisation at https://github.com/choria-io and I have moved all the forge modules to it’s own space as well https://forge.puppet.com/choria.
There are various other places the logo show up like in the Slack notifications and so forth.
On the project front there’s a few improvements:
- There is now a registration plugin that records a bunch of internal stats on disk, the aim is for them to be read by Collectd and Sensu
- A new Auditing plugin that emits JSON structured data
- Several new Data Stores for Playbooks – files, environment.
- Bug fixes on Windows
- All the modules, plugins etc have moved to the Choria Forge and GitHub
- Quite extensive documentation site updates including branding with the logo and logo colors.
There is now very few things left to do to get 1.0.0 out but I guess another release or two will be done before then.
So from now to update to coming versions you need to use the choria/mcollective_choria module which will pull in all it’s dependencies from the Choria project rather than my own Forge.
Still no progress on moving the actual MCollective project forward but I’ve discussed a way to deal with forking the various projects in a way that seems to work for what I want to achieve. In reality I’ll only have time to do that in a couple of months so hopefully something positive will happen in the mean time.
Head over to Choria.io to take a look.
by R.I. Pienaar | Jan 23, 2017 | Code
About a month ago I blogged about Choria Playbooks – a way to write series of actions like MCollective, Shell, Slack, Web Hooks and others – contained within a YAML script with inputs, node sets and more.
Since then I added quite a few tweaks, features and docs, it’s well worth a visit to choria.io to check it out.
Today I want to blog about a major new integration I did into them and a major step towards version 1 for Choria.
Overview
In the context of a playbook or even a script calling out to other system there’s many reasons to have a Data Source. In the context of a playbook designed to manage distributed systems the Data Source needed has some special needs. Needs that tools like Consul and etcd fulfil specifically.
So today I released version 0.0.20 of Choria that includes a Memory and a Consul Data Source, below I will show how these integrate into the Playbooks.
I think using a distributed data store is important in this context rather than expecting to pass variables from the Playbook around like on the CLI since the business of dealing with the consistency, locking and so forth are handled and I can’t know all the systems you wish to interact with, but if those can speak to Consul you can prepare an execution environment for them.
For those who don’t agree there is a memory Data Store that exists within the memory of the Playbook. Your playbook should remain the same apart from declaring the Data Source.
Using Consul
Defining a Data Source
Like with Node Sets you can have multiple Data Sources and they are identified by name:
data_stores:
pb_data:
type: consul
timeout: 360
ttl: 20 |
data_stores:
pb_data:
type: consul
timeout: 360
ttl: 20
This creates a Consul Data Source called pb_data, you need to have a local Consul Agent already set up. I’ll cover the timeout and ttl a bit later.
Playbook Locks
You can create locks in Consul and by their nature they are distributed across the Consul network. This means you can ensure a playbook can only be executed once per Consul DC or by giving a custom lock name any group of related playbooks or even other systems that can make Consul locks.
---
locks:
- pb_data
- pb_data/custom_lock |
---
locks:
- pb_data
- pb_data/custom_lock
This will create 2 locks in the pb_data Data Store – one called custom_lock and another called choria/locks/playbook/pb_name where pb_name is the name from the metadata.
It will try to acquire a lock for up to timeout seconds – 360 here, if it can’t the playbook run fails. The associated session has a TTL of 20 seconds and Choria will renew the sessions around 5 seconds before the TTL expires.
The TTL will ensure that should the playbook die, crash, machine die or whatever, the lock will release after 20 seconds.
Binding Variables
Playbooks already have a way to bind CLI arguments to variables called Inputs. Data Sources extend inputs with extra capabilities.
We now have two types of Input. A static input is one where you give the data on the CLI and the data stays static for the life of the playbook. A dynamic input is one bound against a Data Source and the value of it is fetched every time you reference the variable.
inputs:
cluster:
description: "Cluster to deploy"
type: "String"
required: true
data: "pb_data/choria/kv/cluster"
default: "alpha" |
inputs:
cluster:
description: "Cluster to deploy"
type: "String"
required: true
data: "pb_data/choria/kv/cluster"
default: "alpha"
Here we have a input called cluster bound to the choria/kv/cluster key in Consul. This starts life as a static input and if you give this value on the CLI it will never use the Data Source.
If however you do not specify a CLI value it becomes dynamic and will consult Consul. If there’s no such key in Consul the default is used, but the input remains dynamic and will continue to consult Consul on every access.
You can force an input to be dynamic which will mean it will not show up on the CLI and will only speak to a data source using the dynamic: true property on the Input.
Writing and Deleting Data
Of course if you can read data you should be able to write and delete it, I’ve added tasks to let you do this:
locks:
- pb_data
inputs:
cluster:
description: "Cluster to deploy"
type: "String"
required: true
data: "pb_data/choria/kv/cluster"
default: "alpha"
validation: ":shellsafe"
hooks:
pre_book:
- data:
action: "delete"
key: "pb_data/choria/kv/cluster"
tasks:
- shell:
description: Deploy to cluster {{{ inputs.cluster }}}
command: /path/to/script --cluster {{{ inputs.cluster }}}
- data:
action: "write"
value: "bravo"
key: "pb_data/choria/kv/cluster"
- shell:
description: Deploy to cluster {{{ inputs.cluster }}}
command: /path/to/script --cluster {{{ inputs.cluster }}} |
locks:
- pb_data
inputs:
cluster:
description: "Cluster to deploy"
type: "String"
required: true
data: "pb_data/choria/kv/cluster"
default: "alpha"
validation: ":shellsafe"
hooks:
pre_book:
- data:
action: "delete"
key: "pb_data/choria/kv/cluster"
tasks:
- shell:
description: Deploy to cluster {{{ inputs.cluster }}}
command: /path/to/script --cluster {{{ inputs.cluster }}}
- data:
action: "write"
value: "bravo"
key: "pb_data/choria/kv/cluster"
- shell:
description: Deploy to cluster {{{ inputs.cluster }}}
command: /path/to/script --cluster {{{ inputs.cluster }}}
Here I have a pre_book task list that ensures there is no stale data, the lock ensures no other Playbook will mess around with the data while we run.
I then run a shell command that uses the cluster input, with nothing there it uses the default and so deploys cluster alpha, it then writes a new value and deploys cluster brova.
This is a bit verbose I hope to add the ability to have arbitrarily named tasks lists that you can branch to, then you can have 1 deploy task list and use the main task list to set up variables for it and call it repeatedly.
Conclusion
That’s quite a mouthful, the possibilities of this is quite amazing. On one hand we have a really versatile data store in the Playbooks but more significantly we have expanded the integration possibilities by quite a bit, you can now have other systems manage the environment your playbooks run in.
I will soon add task level locks and of course Node Set integration.
For now only Consul and Memory is supported, I can add others if there is demand.


