Running large or distributed MCollective networks have always been a pain. As much as Middleware is an enabler it starts actively working against you as you grow and as latency increases, this is felt especially when you have geographically distributed networks.
Federation has been discussed often in the past but nothing ever happened, NATS ended up forcing my hand because it only supports a full mesh mode. Something that would not be suitable for a globe spanning network.
Overview
I spent the last week or two building in Federation first into the Choria network protocol and later added a Federation Broker. Federation can be used to connect entirely separate collectives together into one from the perspective of a client.
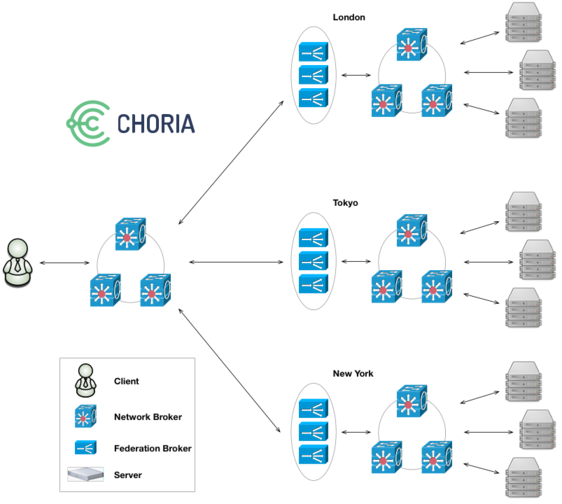
Here we can see a distributed Federation of Collectives. Effectively London, Tokyo and New York are entirely standalone collectives. They are smaller, they have their own middleware infrastructure, they even function just like a normal collective and can have clients communicating with those isolated collectives like always.
I set up 5 node NATS meshes in every region. We then add a Federation Broker cluster that provide bridging services to a central Federation network. I’d suggest running the Federation Broker Cluster one instance on each of your NATS nodes, but you can run as many as you like.
Correctly configured Clients that connect to the central Federation network will interact with all the isolated collectives as if they are one. All current MCollective features keep working and Sub Collectives can span the entire Federation.
Impact
There are obvious advantages in large networks – instead of one giant 100 000 node middleware you now need to built 10 x 10 000 node networks, something that is a lot easier to do. With NATS, it’s more or less trivial.
Not so obvious is how this scales wrt MCollective. MCollective has a mode called Direct Addressing where the client would need to create 1 message for every node targeted in the request. Generally very large requests are discouraged so it works ok.
These requests being made on the client ends up having to travel individually all across the globe and this is where it starts to hurt.
With Federation the client will divide the task of producing these per client messages into groups of 200 and pass the request to the Federation Broker Cluster. The cluster will then, in a load shared fashion, do the work for the client.
Since the Federation Broker tends to be near the individual Collectives this yields a massive reduction in client work and network traffic. The Federation Broker Instances are entirely state free so you can run as many as you like and they will share the workload more or less evenly across them.
$ mco federation observe --cluster production
Federation Broker: production
Federation
Totals:
Received: 1024 Sent: 12288
Instances:
1: Received: 533 (52.1%) Sent: 6192 (50.4%)
2: Received: 491 (47.9%) Sent: 6096 (49.6%) |
Above you can see the client offloading the work onto a Federation Broker with 2 cluster members. The client sent 1024 messages but the broker sent 12288 messages on the clients behalf. The 2 instances does a reasonable job of sharing the load of creating and federating the messages across them.
In my tests against large collectives this speeds up the request significantly and greatly reduce the client load.
In the simple broadcast case there is no speed up, but when doing 10 000 requests in a loop the overhead of Federation was about 2 seconds over the 10 000 requests – so hardly noticeable.
Future Direction
The Choria protocol supports Federation in a way that is not tied to its specific Federation Broker implementation. The basic POC Federation Broker was around 200 lines so not really a great challenge to write.
I imagine in time we might see a few options here:
- You can use different CAs in various places in your Federated network. The Federation Broker using Choria Security privileged certificates can provide user id mapping and rewriting between the Collectives
- If you want to build a SaaS management services ontop of Choria a Federated network makes a really safe way to reach into managed networks without exposing the collectives to each other in any way. A client in one member Collective cannot use the Federation Brokers to access another Collective.
- Custom RBAC and Auditing schemes can be built at the Federation Broker layer where the requests can be introspected and only ones matching policy are passed to the managed Collective
- Federation is tailor made to provide Protocol translation. Different protocol Collectives can be bridged together. An older MCollective SSL based collective can be reached from a Choria collective via a Federation Broker providing translation capabilities. Ditto a Websocket interface to Collectives can be a Federation Broker listening on Websocket while speaking NATS on the other end.
The security implications are huge, isolated collectives with isolated CAs and unique user Auditing, Authorization and Authentication needs bridged together via a custom RBAC layer, one that is horizontally scalable and stateless is quite a big deal.
Protocol translation is equally massive, as I move towards looking at ways to fork MCollective, given the lack of cooperation from Puppet Inc, this gives me a very solid way forward to not throw away peoples investment in older MCollective while wishing to find a way to move forward.
Availability
This will be released in version 0.0.25 of the Choria module which should be sometime this week. I’ve published pre-release docs already. Expect it to be deployable with very little effort via Puppet, given a good DNS setup it needs almost no configuration at all.
I’ll make a follow up post that explores the network protocol that made this possible to build with zero stored state in the Federation Broker Instances – a major achievement in my book.
UPDATE: All the gory protocol details are in a follow up post Choria Network Protocols – Transport.
