by R.I. Pienaar | Apr 19, 2016 | Code
A while ago I released a Puppet 4 Hiera based node classifier to see what is next for hiera_include(). This had the major drawback that you couldn’t set an environment with it like with a real ENC since Puppet just doesn’t have that feature.
I’ve released a update to the classifier that now include a small real ENC that takes care of setting the environment based on certname and then boots up the classifier on the node.
Usage
ENCs tend to know only about the certname, you could imagine getting most recent seen facts from PuppetDB etc but I do not really want to assume things about peoples infrastructure. So for now this sticks to supporting classification based on certname only.
It’s really pretty simple, lets assume you are wanting to classify node1.example.net, you just need to have a node1.example.net.yaml (or JSON) file somewhere in a path. Typically this is going to be in a directory environment somewhere but could of course also be a site wide hiera directory.
In it you put:
classifier::environment: development |
classifier::environment: development
And this will node will form part of that environment. Past that everything in the previous post just applies so you make rules or assign classes as normal, and while doing so you have full access to node facts.
The classifier now expose some extra information to help you determine if the ENC is in use and based on what file it’s classifying the node:
-
$classifier::enc_used – boolean that indicates if the ENC is in use
-
$classifier::enc_source – path to the data file that set the environment. undef when not found
-
$classifier::enc_environment – the environment the ENC is setting
It supports a default environment which you configure when configuring Puppet to use a ENC as below.
Configuring Puppet
Configuring Puppet is pretty simple for this:
[main]
node_terminus = exec
external_nodes = /usr/local/bin/classifier_enc.rb --data-dir /etc/puppetlabs/code/hieradata --node-pattern nodes/%%.yaml |
[main]
node_terminus = exec
external_nodes = /usr/local/bin/classifier_enc.rb --data-dir /etc/puppetlabs/code/hieradata --node-pattern nodes/%%.yaml
Apart from these you can do –default development to default to that and not production and you can add –debug /tmp/enc.log to get a bunch of debug output.
The data-dir above is for your classic Hiera single data dir setup, but you can also use globs to support environment data like –data-dir /etc/puppetlabs/code/environments/*/hieradata. It will now search the entire glob until it finds a match for the certname.
That’s really all there is to it, it produce a classification like this:
---
environment: production
classes:
classifier:
enc_used: true
enc_source: /etc/puppetlabs/code/hieradata/node.example.yaml
enc_environment: production |
---
environment: production
classes:
classifier:
enc_used: true
enc_source: /etc/puppetlabs/code/hieradata/node.example.yaml
enc_environment: production
Conclusion
That’s really all there is to it, I think this might hit a high percentage of user cases and bring a key ability to the hiera classifiers. It’s a tad annoying there is no way really to do better granularity than just per node here, I might come up with something else but don’t really want to go too deep down that hole.
In future I’ll look about adding a class to install the classifier into some path and configure Puppet, for now that’s up to the user. It’s shipped in the bin dir of the module.
by R.I. Pienaar | Feb 26, 2012 | Code
I have a number of mail servers where mail enters, get spam scanned etc and then forwarded to mail box servers. This used to be customer facing and had web interfaces and statistics etc but I am now scaling all this down to just manage my own and some friends domains.
Rather than maintain all the web interfaces that I really could not care for I’d rather manage this with Puppet, my ideal end result would be:
exim::route{"devco.net":
nexthop => "my.mailbox.server",
spamthreshold => 10,
spamdestination => ":blackhole:",
has_greylist => 1,
has_spam_check => 1,
has_whitelist => 1
} |
exim::route{"devco.net":
nexthop => "my.mailbox.server",
spamthreshold => 10,
spamdestination => ":blackhole:",
has_greylist => 1,
has_spam_check => 1,
has_whitelist => 1
}
This should add all the required configuration to deliver mail arriving at the mail relay for devco.net to the server my.mailbox.server. It will set up Spam Assassin scans and send all mail that scores more than 10 to the exim specific destination :blackhole: that would simply delete the mail. I could specify any valid mail destination here like a file or other email address. I won’t be covering the has_* entries in this guide, they just control various policies in my ACLs on a per domain basis.
I’ll first cover the Exim side of things, clearly I do not want to be editing exim.conf each time so I will read the domain information from a file stored on the server. These files will be stored in /etc/exim/routes/devco.net and look like:
nexthop: my.mailbox.server
spamthreshold: 10
spamdestination: :blackhole: |
nexthop: my.mailbox.server
spamthreshold: 10
spamdestination: :blackhole:
In order to accept mail for a domain Exim needs a list of valid domains it will accept mail for, so as our routes are named after the domain we can just leverage that to build the list:
domainlist mw_domains = dsearch;/etc/exim/routes |
domainlist mw_domains = dsearch;/etc/exim/routes
Next we should pull from the file the various settings we store there:
NEXTHOP = ${lookup{nexthop}lsearch{/etc/exim/routes/${domain}}}
DOMAINREJECTSCORE = ${eval:10*${lookup{spamthreshold}lsearch{/etc/exim/routes/${domain}}}}
DOMAINSPAMDEST = ${lookup{spamdestination}lsearch{/etc/exim/routes/${domain}}}
ACL_SPAMSCORE = acl_m3 |
NEXTHOP = ${lookup{nexthop}lsearch{/etc/exim/routes/${domain}}}
DOMAINREJECTSCORE = ${eval:10*${lookup{spamthreshold}lsearch{/etc/exim/routes/${domain}}}}
DOMAINSPAMDEST = ${lookup{spamdestination}lsearch{/etc/exim/routes/${domain}}}
ACL_SPAMSCORE = acl_m3
This creates handy variables that we can just use in our routes and spam configuration, I won’t go into the actual setup of spam assassin scanning as that’s pretty standard stuff better documented elsewhere. In the spam assassin ACLs just store your $spam_score_int in ACL_SPAMSCORE.
To deliver the mail either to the specific spam destination or to the next hop we just need to add 2 routers to the routes section. These are order dependant so they should be in the order below:
spamblock:
driver = redirect
condition = ${if >= {$ACL_SPAMSCORE}{DOMAINREJECTSCORE}{true}{false}}
data = DOMAINSPAMDEST
headers_add = X-MW-Note: Redirecting mail to domain spam destination
domains = +mw_domains
no_verify |
spamblock:
driver = redirect
condition = ${if >= {$ACL_SPAMSCORE}{DOMAINREJECTSCORE}{true}{false}}
data = DOMAINSPAMDEST
headers_add = X-MW-Note: Redirecting mail to domain spam destination
domains = +mw_domains
no_verify
Here we’re just doing a quick if check over the stored spam score to see if its bigger or equal to the threshold stored in DOMAINREJECTSCORE and then set the data of the route – where the mail should go – to the configured address from DOMAINSPAMDEST. This router will only be active for domains that this Exim server is a relay for and it adds a little debug note as a header.
The actual mail delivery that is being used in place of the normal dnslookup route is here:
mw_domains:
driver = manualroute
transport = remote_smtp
domains = +mw_domains
user = root
headers_add = "X-MW-Recipient: ${local_part}@${domain}\n\
X-MW-Sender: $sender_address\n\
X-MW-Server: $primary_hostname"
route_data = MW_NEXTHOP |
mw_domains:
driver = manualroute
transport = remote_smtp
domains = +mw_domains
user = root
headers_add = "X-MW-Recipient: ${local_part}@${domain}\n\
X-MW-Sender: $sender_address\n\
X-MW-Server: $primary_hostname"
route_data = MW_NEXTHOP
This router is also restricted to only our relay domains, it adds some headers for debug purposes and finally sets the route_data of the email to the next hop from MW_NEXTHOP thus delivering the mail to the destination.
That’s all there is to do on the Exim side, it’s pretty standard stuff. Next up the Puppet define:
define exim::route($nexthop, $spamthreshold, $spamdestination, $ensure = "present") {
file{"/etc/exim/routes/${name}":
ensure => $ensure,
content => template("exim/route.erb")
}
} |
define exim::route($nexthop, $spamthreshold, $spamdestination, $ensure = "present") {
file{"/etc/exim/routes/${name}":
ensure => $ensure,
content => template("exim/route.erb")
}
}
And the template for this define is also extremely simple:
nexthop: <%= nexthop %>
spamthreshold: <%= spamthreshold %>
spamdestination: <%= spamdestination %> |
nexthop: <%= nexthop %>
spamthreshold: <%= spamthreshold %>
spamdestination: <%= spamdestination %>
I could stop here and just create a bunch of exim::route resources but that would be code changes, I prefer just changing data. So I am going to create a JSON file called mailrelay.json and store it with my Hiera data.
{
"relay_domains": {
"devco.net": {
"nexthop": "my.mailbox.server",
"spamdestination": ":blackhole:",
"spamthreshold": 10,
"has_dkim": 1
},
"another.com": {
"nexthop": "ASPMX.L.GOOGLE.COM.",
"spamdestination": ":blackhole:",
"spamthreshold": 10
}
}
} |
{
"relay_domains": {
"devco.net": {
"nexthop": "my.mailbox.server",
"spamdestination": ":blackhole:",
"spamthreshold": 10,
"has_dkim": 1
},
"another.com": {
"nexthop": "ASPMX.L.GOOGLE.COM.",
"spamdestination": ":blackhole:",
"spamthreshold": 10
}
}
}
I assign all my incoming mail servers a single class that would look roughly like this:
class roles::mailrelay {
include exim
include exim::mailrelay
$routes = hiera("relay_domains", "", "mailrelay")
$domains = keys($routes)
exim::routemap{$domains:
routes => $routes
}
} |
class roles::mailrelay {
include exim
include exim::mailrelay
$routes = hiera("relay_domains", "", "mailrelay")
$domains = keys($routes)
exim::routemap{$domains:
routes => $routes
}
}
The call to Hiera fetches the entire hash from the mailrelay.json file and stores it in $routes. I then use the keys function from puppetlabs-stdlib to extract just the list of domains into an array. I then pass that into a define exim::routemap that iterates the list and builds up individual exim::route resources.
The routemap define is just as below, I’ve shortened it a fair bit as I also have validation logic in here to make sure I pass valid data in the hash from Hiera, the stdlib module has various validator functions thats really handy for this:
define exim::routemap($routes) {
exim::route{$name:
nexthop => $routes[$name]["nexthop"],
spamthreshold => $routes[$name]["spamthreshold"],
spamdestination => $routes[$name]["spamdestination"]
}
if ($routes[$name]["has_dkim"] == 1) {
exim::dkim_domain{$name: }
} else {
exim::dkim_domain{$name: ensure => absent}
}
} |
define exim::routemap($routes) {
exim::route{$name:
nexthop => $routes[$name]["nexthop"],
spamthreshold => $routes[$name]["spamthreshold"],
spamdestination => $routes[$name]["spamdestination"]
}
if ($routes[$name]["has_dkim"] == 1) {
exim::dkim_domain{$name: }
} else {
exim::dkim_domain{$name: ensure => absent}
}
}
And that’s about it, now my mail routing setup, DKIM signing and other policies are managed in a simple JSON file in my Puppet Manifests.
by R.I. Pienaar | Jun 11, 2011 | Uncategorized
Note: This project is now being managed by Puppetlabs, its new home is http://projects.puppetlabs.com/projects/hiera
Last week I posted the first details about my new data source for Hiera that enables its use in Puppet.
In that post I mentioned I want to do merge or array searches in the future. I took a first stab at that for array data and wanted to show how that works. I also mentioned I wanted to write a Hiera External Node Classifier (ENC) but this work completely makes that redundant now in my mind.
A common pattern you see in ENCs are that they layer data – very similar in how extlookup / hiera has done it – but that instead of just doing a first-match search they combine the results into a merged list. This merged list is then used to include the classes on the nodes.
For a node in the production environment located in dc1 you’ll want:
node default {
include users::common
include users::production
include users::dc1
} |
node default {
include users::common
include users::production
include users::dc1
}
I’ve made this trivial in Hiera now, given the 3 files below:
common.json
{"classes":"users::common"}
production.json
{"classes":"users::production"}
dc1.json
{"classes":"users::dc1"}
And appropriate Hiera hierarchy configuration you can achieve this using the node block below:
node default {
hiera_include("classes")
} |
node default {
hiera_include("classes")
}
Any parametrized classes that use Hiera as in my previous post will simply do the right thing. Individual classes variables can be arrays so you can include many classes at each tier. Now just add a role fact on your machines, add a role tier in Hiera and you’re all set.
The huge win here is that you do not need to do any stupid hacks like load the facts from the Puppet Masters vardir in your ENC to access the node facts or any of the other hacky things people do in ENCs. This is simply a manifest doing what manifests do – just better.
The hiera CLI tool has been updated with array support, here is it running on the data above:
$ hiera -a classes
["users::common"]
$ hiera -a classes environment=production location=dc1
["users::common", "users::production", "users::dc1"]
I’ve also added a hiera_array() function that takes the same parameters as the hiera() function but that returns an array of the found data. The array capability will be in Hiera version 0.2.0 which should be out later today.
I should also mention that Luke Kanies took a quick stab at integrating Hiera into Puppet and the result is pretty awesome. Given the example below Puppet will magically use Hiera if it’s available, else fall back to old behavior.
class ntp::config($ntpservers="1.pool.ntp.org") {
.
.
}
node default {
include ntp::config
} |
class ntp::config($ntpservers="1.pool.ntp.org") {
.
.
}
node default {
include ntp::config
}
With Lukes proposed changes this would be equivalent to:
class ntp::config($ntpservers=hiera("ntpservers", "1.pool.ntp.org")) {
.
.
} |
class ntp::config($ntpservers=hiera("ntpservers", "1.pool.ntp.org")) {
.
.
}
This is pretty awesome. I wouldn’t hold my breath to see this kind of flexibility soon in Puppet core but it shows whats possible.
by R.I. Pienaar | Jun 6, 2011 | Uncategorized
Note: This project is now being managed by Puppetlabs, its new home is http://projects.puppetlabs.com/projects/hiera
Yesterday I released a Hierarchical datastore called Hiera, today as promised I’ll show how it integrates with Puppet.
Extlookup has solved the basic problem of loading data into Puppet. This was done 3 years ago at a time before Puppet supported complex data in Hashes or things like Parametrized classes. Now as Puppet has improved a new solution is needed. I believe the combination of Hiera and the Puppet plugin goes a very long way to solving this and making parametrized classes much more bearable.
I will highlight a sample use case where a module author places a module on the Puppet Forge and a module user downloads and use the module. Both actors need to create data – the author needs default data to create a just-works experience and the module user wants to configure the module behavior either in YAML, JSON, Puppet files or anything else he can code.
Module Author
The most basic NTP module can be seen below. It has a ntp::config class that uses Hiera to read default data from ntp::data:
modules/ntp/manifests/config.pp
class ntp::config($ntpservers = hiera("ntpservers")) {
file{"/tmp/ntp.conf":
content => template("ntp/ntp.conf.erb")
}
} |
class ntp::config($ntpservers = hiera("ntpservers")) {
file{"/tmp/ntp.conf":
content => template("ntp/ntp.conf.erb")
}
}
modules/ntp/manifests/data.pp
class ntp::data {
$ntpservers = ["1.pool.ntp.org", "2.pool.ntp.org"]
} |
class ntp::data {
$ntpservers = ["1.pool.ntp.org", "2.pool.ntp.org"]
}
This is your most basic NTP module. By using hiera(“ntpserver”) you load $ntpserver from these variables, the first one that exists gets used. In this case the last one.
- $ntp::config::data::ntpservers
- $ntp::data:ntpservers
This would be an abstract from a forge module, anyone who use it will be configured to use the ntp.org base NTP servers.
Module User
As a user I really want to use this NTP module from the Forge and not write my own. But what I also need is flexibility over what NTP servers I use. Generally that means forking the module and making local edits. Parametrized Classes are supposed to make this better but sadly the design decisions means you need an ENC or a flexible data store. The data store was missing thus far and I really would not recommend their use without it.
Given that the NTP module above is using Hiera as a user I now have various options to override its use. I configure Hiera to use the (default) YAML backend for data but to also load in the Puppet backend should the YAML one not provide an answer. I also configure it to allow me to create per-location data that gives me the flexibility I need to pick NTP servers I need.
:backends: - yaml
- puppet
:hierarchy: - %{location}
- common |
:backends: - yaml
- puppet
:hierarchy: - %{location}
- common
I now need to decide how best to override the data from the NTP module:
I want:
- Per datacenter values when needed. The NOC at the data center can change this data without change control.
- Company wide policy the should apply over the module defaults. This is company policy and should be subject to change control like my manifests.
Given these constraints I think the per-datacenter policy can go into data files that is controlled outside of my VCS like with a web application or simple editor. The common data that should apply company wide need to be controlled under my VCS and managed by the change control board.
Hiera makes this easy. By configuring it as above the new Puppet data search path – for a machine in dc1 – would be:
- $data::dc1::ntpservers – based on the Hiera configuration, user specific
- $data::common::ntpservers – based on the Hiera configuration, user specific
- $ntp::config::data::ntpservers – users do not touch this, it’s for module authors
- $ntp::data:ntpservers – users do not touch this, it’s for module authors
You can see this extends the list seen above, the module author data space remain in use but we now have a layer on top we can use.
First we create the company wide policy file in Puppet manifests:
modules/data/manifests/common.pp
class data::common {
$ntpservers = ["ntp1.example.com", "ntp2.example.com"]
} |
class data::common {
$ntpservers = ["ntp1.example.com", "ntp2.example.com"]
}
As Hiera will query this prior to querying any in-module data this will effectively prevent any downloaded module from supplying NTP servers other than ours. This is a company wide policy that applies to all machines unless specifically configured otherwise. This lives with your code in your SCM.
Next we create the data file for machines with fact $location=dc1. Note this data is created in a YAML file outside of the manifests. You can use JSON or any other Hiera backend so if you had this data in a CMDB in MySQL you could easily query the data from there:
hieradb/dc1.yaml
---
ntpservers: - ntp1.dc1.example.com
- ntp2.dc1.example.com |
---
ntpservers: - ntp1.dc1.example.com
- ntp2.dc1.example.com
And this is the really huge win. You can create Hiera plugins to get this data from anywhere you like that magically override your in-manifest data.
Finally here are a few Puppet node blocks:
node "web1.prod.example.com" {
$location = "dc1"
include ntp::config
}
node "web1.dev.example.com" {
$location = "office"
include ntp::config
}
node "oneoff.example.com" {
class{"ntp::config":
ntpservers => ["ntp1.isp.net"]
}
} |
node "web1.prod.example.com" {
$location = "dc1"
include ntp::config
}
node "web1.dev.example.com" {
$location = "office"
include ntp::config
}
node "oneoff.example.com" {
class{"ntp::config":
ntpservers => ["ntp1.isp.net"]
}
}
These 3 nodes will have different NTP configurations based on their location – you should really make $location a fact:
-
web1.prod will use ntp1.dc1.example.com and ntp2.dc1.example.com
-
web1.dev will use the data from class data::common
-
oneoff.example.com is a complete weird case and you can still use the normal parametrized syntax – in this case Hiera wont be involved at all.
And so we have a very easy to use a natural blend between using param classes from an ENC for full programmatic control without sacrificing the usability for beginner users who can not or do not want to invest the time to create an ENC.
The plugin is available on GitHub as hiera-puppet and you can just install the hiera-puppet gem. You will still need to install the Parser Function into your master until the work I did to make Puppet extendable using RubyGems is merged.
The example above is on GitHub and you can just use that to test the concept and see how it works without the need to plug into your Puppet infrastructure first. See the README.
The Gem includes extlookup2hiera that can convert extlookup CSV files into JSON or YAML.
by R.I. Pienaar | Jun 5, 2011 | Uncategorized
Note: This project is now being managed by Puppetlabs, its new home is http://projects.puppetlabs.com/projects/hiera
In my previous post I presented a new version of extlookup that is pluggable. This is fine but it’s kind of tightly integrated with Puppet and hastily coded. That code works – and people are using it – but I wanted a more mature and properly standalone model.
So I wrote a new standalone non-puppet related data store that takes the main ideas of using Hierarchical data present in extlookup and made it generally available.
I think the best model for representing key data items about infrastructure is using a Hierarchical structure.
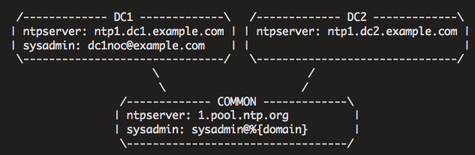
The image above shows the data model visually, in this case we need to know the Systems Administrator contact as well as the NTP servers for all machines.
If we had production machines in dc1, dc2 and our dev/testing in our office this model will give the Production machines specific NTP servers while the rest would use the public NTP infrastructure. DC1 would additional have a specific Systems Admin contact, perhaps it’s outsourced to your DR provider.
This is the model that extlookup exposed to Puppet and that a lot of people are using extensively.
Hiera extracts this into a standalone project and ships with a YAML backend by default, there are also JSON and Puppet ones available.
It extends the old extlookup model in a few key ways. It has configuration files of it’s own rather than rely on Puppet. You can chain multiple data sources together and the data directories are now subject to scope variable substitution.
The chaining of data sources is a fantastic ability that I will detail in a follow up blog post showing how you would use this to create reusable modules and make Puppet parametrized classes usable – even without an ENC.
It’s available as a gem using the simple gem install hiera and the code is on GitHub where there is an extensive README. There is also a companion project that let you use JSON as data store – gem install hiera-json. These are the first Gems I have made in years so no doubt they need some love, feedback appreciated in GitHub issues.
Given the diagram above and data setup to match you can query this data from the CLI, examples of the data is @ GitHub:
$ hiera ntpserver location=dc1
ntp1.dc1.example.com |
$ hiera ntpserver location=dc1
ntp1.dc1.example.com
If you were on your Puppet Master or had your node Fact YAML files handy you can use those to provide the scope, here the yaml file has a location=dc2 fact:
$ hiera ntpserver --yaml /var/lib/puppet/yaml/facts/example.com
ntp1.dc2.example.com |
$ hiera ntpserver --yaml /var/lib/puppet/yaml/facts/example.com
ntp1.dc2.example.com
I have a number of future plans for this:
- Currently you can only do priority based searches. It will also support merge searches where each tier will contribute to the answer. The answer will be a merged hash
- A Puppet ENC should be written based on this data. This will require the merge searches mentioned above.
- More backends
- A webservice that can expose the data to your infrastructure
- Tools to create the data – this should really be Foreman and/or Puppet Dashboard like tools but certainly CLI ones should exist too.
I have written a new Puppet backend and Puppet function that can query this data. This has turned out really great and I will make a blog post dedicated to that later, for now you can see the README for that project for details. This backend lets you override in-module data supplied inside your manifests using external data of your choice. Definitely check it out.
