by R.I. Pienaar | Dec 26, 2016 | Uncategorized
Today I am very pleased to release something I’ve been thinking about for years and actively working on since August.
After many POCs and thrown away attempts at this over the years I am finally releasing a Playbook system that lets you run work flows on your MCollective network – it can integrate with a near endless set of remote services in addition to your MCollective to create a multi service playbook system.
This is a early release with only a few integrations but I think it’s already useful and I’m looking for feedback and integrations to build this into something really powerful for the Puppet eco system.
The full docs can be found on the Choria Website, but below you can get some details.
Overview
Today playbooks are basic YAML files. Eventually I envision a Service to execute playbooks on your behalf, but today you just run them in your shell, so they are pure data.
Playbooks have a basic flow that is more or less like this:
- Discover named Node Sets
- Validate the named Node Sets meet expectations such as reachability and versions of software available on them
- Run a pre_book task list that lets you do prep work
- Run the main tasks task list where you do your work, around every task certain hook lists can be run
- Run either the on_success or on_fail task list for notification of Slacks etc
- Run the post_book task list for cleanups etc
Today a task can be a MCollective request, a shell script or a Slack notification. I imagine this list will grow huge, I am thinking you will want to ping webhooks, or interact with Razor to provision machines and wait for them to finish building, run Terraform or make EC2 API requests. This list of potential integrations is endless and you can use any task in any of the above task lists.
A Node Set is simply a named set of nodes, in MCollective that would be certnames of nodes but the playbook system itself is not limited to that. Today Node Sets can be resolved from MCollective Discovery, PQL Queries (PuppetDB), YAML files with groups of nodes in them or a shell command. Again the list of integrations that make sense here is huge. I imagine querying PE or Foreman for node groups, querying etcd or Consul for service members. Talking to random REST services that return node lists or DB queries. Imagine using Terraform outputs as Node Set sources or EC2 API queries.
In cases where you wish to manage nodes via MCollective but you are using a cached discovery source you can ask node sets to be tested for reachability over MCollective. And node sets that need certain MCollective agents can express this desire as SemVer version ranges and the valid network state will be asserted before any playbook is run.
Playbooks do not have a pseudo programming language in them though I am not against the idea. I do not anticipate YAML to be the end format of playbooks but it’s good enough for today.
Example
I’ll show an example here of what I think you will be able to achieve using these Playbooks.
Here we have a web stack and we want to do Blue/Green deploys against it, sub clusters have a fact cluster. The deploy process for a cluster is:
- Gather input from the user such as cluster to deploy and revision of the app to deploy
- Discover the Haproxy node using Node Set discovery from PQL queries
- Discover the Web Servers in a particular cluster using Node Set discovery from PQL queries
- Verify the Haproxy nodes and Web Servers are reachable and running the versions of agents we need
- Upgrade the specific web tier using:
- Tell the ops room on slack we are about to upgrade the cluster
- Disable puppet on the webservers
- Wait for any running puppet runs to stop
- Disable the nodes on a particular haproxy backend
- Upgrade the apps on the servers using appmgr#upgrade to the input revision
- Do up to 10 NRPE checks post upgrade with 30 seconds between checks to ensure the load average is GREEN, you’d use a better check here something app specific
- Enable the nodes in haproxy once NRPE checks pass
- Fetch and display the status of the deployed app – like what version is there now
- Enable Puppet
Should the task list all FAIL we run these tasks:
- Call a webhook on AWS Lambda
- Tell the ops room on slack
- Run a whole other playbook called deploy_failure_handler with the same parameters
Should the task list PASS we run these tasks:
- Call a webhook on AWS Lambda
- Tell the ops room on slack
This example and sample playbooks etc can be found on the Choria Site.
Status
Above is the eventual goal. Today the major missing piece here that I think MCollective needs to be extended with the ability for Agent plugins to deliver a Macro plugin. A macro might be something like Puppet.wait_till_idle(:timeout => 600), this would be something you call after disabling the nodes and you want to be sure Puppet is making no more changes, you can see the workflow above needs this.
There is no such Macros today, I will add a stop gap solution as a task that waits for a certain condition but adding Macros to MCollective is high on my todo list.
Other than that it works, there is no web service yet so you run them from the CLI and the integrations listed above is all that exist, they are quite easy to write so hoping some early adopters will either give me ideas or send PRs!
This is available today if you upgrade to version 0.0.12 of the ripienaar-mcollective_choria module.
See the Choria Website for much more details on this feature and a detailed roadmap.
UPDATE: Since posting this blog I had some time and added: Terraform Node Sets, ability to create GET and POST Webhook requests and the much needed ability to assert and wait for remote state.
by R.I. Pienaar | Dec 13, 2016 | Uncategorized
Some time ago I mentioned that I am working on improving the MCollective Deployment story.
I started a project called Choria that aimed to massively improve the deployment UX and yield a secure and stable MCollective setup for those using Puppet 4.
The aim is to make installation quick and secure, towards that it seems a common end to end install from scratch by someone new to project using a clustered NATS setup can take less than a hour, this is a huge improvement.
Further I’ve had really good user feedback, especially around NATS. One user reports 2000 nodes on a single NATS server consuming 300MB RAM and it being very performant, much more so than the previous setup.
It’s been a few months, this is whats changed:
- The module now supports every OS AIO Puppet supports, including Windows.
- Documentation is available on choria.io, installation should take about a hour max.
- The PQL language can now be used to do completely custom infrastructure discovery against PuppetDB.
- Many bugs have been fixed, many things have been streamlined and made more easy to get going with better defaults.
- Event Machine is not needed anymore.
- A number of POC projects have been done to flesh out next steps, things like a very capable playbook system and a revisit to the generic RPC client, these are on GitHub issues.
Meanwhile I am still trying to get to a point where I can take over maintenance of MCollective again, at first Puppet Inc was very open to the idea but I am afraid it’s been 7 months and it’s getting nowhere, calls for cooperation are just being ignored. Unfortunately I think we’re getting pretty close to a fork being the only productive next step.
For now though, I’d say the Choria plugin set is production ready and stable any one using Puppet 4 AIO should consider using these – it’s about the only working way to get MCollective on FOSS Puppet now due to the state of the other installation options.
by R.I. Pienaar | Mar 30, 2015 | Uncategorized
I recently blogged about my workflow improvements realised by using docker for some services. Like everyone else the full story about running containers in production is a bit of an unknown. I am running 7 or 8 things in containers at the moment but I have a lot of outstanding questions.
I could go the route of a private PaaS where you push an image or Dockerfile into it and forget about it. Hoping you never have to debug anything or dive deep into finding out why something is not performant as those tend to be very much closed systems. Some like deis are just Docker underneath but some others like the recently hyped lattice.cf unpacks the Docker container and transforms it into something else entirely that is much harder to interact with from a debug perspective. As a bit of an old school sysadmin this fire-and-hope-for-the-best approach leaves me a bit cold. I do not want to lose the ability to carefully observe my running containers using traditional tools if I have to. It’s great to strive for never having to do that, never having to touch a running app using any thing but your monitoring SaaS or that you can just always scale out horizontally but personally I feel I need a bit more closer to the bits interaction at times. Aim for that goal and get a much better overall system, but while you’ve not yet reached this nirvana like state you’re going to want to get at your running apps using strace if it has to.
So having ruled out just running one of the existing crop of private PaaS offerings locally I started thinking about what a container is really. I consider them to be analogous to a package so we need to first explore what Packages are. In it’s simplest form a package is just a bunch of files packaged up. So what makes it better than a tarball?
- Metadata like name, version, build time, build host, dependencies, descriptions, licence, signature and urls
- Built in logic like pre/post install scripts but also companion scripts like init system scripts, monitoring logic etc
- An API to interact with this – the rpm or apt/deb commands – but like in the case of Yum also libraries for interacting with these
All of the above combines to bring the biggest and ultimate benefit from a package: Strong set of companion tools to build, host, deploy, validate, update and inspect those packages. You cannot have the main benefit from packages without the mature implementations of the preceding points.
To really put it in perspective, the Puppet or Chef package resources only works because of the combination of the above 3 points. Without them it will fail which is why the daily attempts by people on #puppet for example to reinvent packaging with a exec running wget and make ends up failing and yield the predictable answer of packaging up your software instead.
When I look at the current state of a docker container and the published approaches for building them I am left a bit wanting when I compare them to a mature package manager wrt to the 3 points above. This means without improvement I am going to end up with a unsatisfactory set of tools and interactions with my running apps.
So to address this I started looking at standardising my builds and creating a framework for building containers the way I like to and what kind of information I would be able to make available to create the tooling I think is needed. I do this using a base image that has a script called container in it that can introspect metadata about the image. Any image downstream from this base image can just add more metadata and hook into the life cycle my container management script provides. It’s not OS dependent so I wouldn’t be forcing any group into a OS choice and can still gain a lot of the advantages Docker brings wrt to making heterogeneous environments less painful. My build system embeds the metadata into any container it builds as JSON files.
Metadata
There are lots going on in this space, Kubernetes has labels and Docker is getting metadata but these are tools to enable metadata, it is still up to users to decide what to do with it.
The reason you want to be able to really interact with and introspect packages come down to things like auditing them. Where do you have outdated SSL versions and the like. Likewise I want to know things about my containers and images:
- Where and when was it built and why
- What was it’s ancestor images
- How do I start, validate, monitor and update it
- What git repo is being built, what hash of that git repo was built
- What are all the tags this specific container is known as at time of build
- What’s the project name this belongs to
- Have the ability to have arbitrary user supplied rich metadata
All that should be visible to the inside and outside of the container and kept for every ancestor of the container. Given this I can create rich generic management tools: I can create tools that do not require configuration to start, update and validate the functionality as well as monitor and extract metrics of any container without any hard coded logic.
Here’s an example:
% docker exec -ti rbldnsd container --metadata|json_reformat
{
"validate_method": "/srv/support/bin/validate.sh",
"start_method": "/srv/support/bin/start.sh",
"update_method": "/srv/support/bin/update.sh"
"validate": true,
"build_cause": "TIMERTRIGGER",
"build_tag": "jenkins-docker rbldnsd-55",
"ci": true,
"image_tag_names": [
"hub.my.net/ripienaar/rbldnsd"
],
"project": "rbldnsd",
"build_time": "2015-03-30 06:02:10",
"build_time_stamp": 1427691730,
"image_name": "ripienaar/rbldnsd",
"gitref": "e1b0a445744fec5e584919711cafd8f4cebdee0e",
} |
% docker exec -ti rbldnsd container --metadata|json_reformat
{
"validate_method": "/srv/support/bin/validate.sh",
"start_method": "/srv/support/bin/start.sh",
"update_method": "/srv/support/bin/update.sh"
"validate": true,
"build_cause": "TIMERTRIGGER",
"build_tag": "jenkins-docker rbldnsd-55",
"ci": true,
"image_tag_names": [
"hub.my.net/ripienaar/rbldnsd"
],
"project": "rbldnsd",
"build_time": "2015-03-30 06:02:10",
"build_time_stamp": 1427691730,
"image_name": "ripienaar/rbldnsd",
"gitref": "e1b0a445744fec5e584919711cafd8f4cebdee0e",
}
Missing from this is monitoring and metrics related bits as those are still a work in progress. But you can see here metadata for a lot of the stuff I mentioned. Images I build embeds this into the image, this means when I FROM one of my images I get a history, that I can examine:
% docker exec -ti rbldnsd container --examine
Container first started at 2015-03-30 05:02:37 +0000 (1427691757)
Container management methods:
Container supports START method using command /srv/support/bin/start.sh
Container supports UPDATE method using command /srv/support/bin/update.sh
Container supports VALIDATE method using command /srv/support/bin/validate.sh
Metadata for image centos_base
Names:
Project Name: centos_base
Image Name: ripienaar/centos_base
Image Tag Names: hub.my.net/ripienaar/centos_base
Build Info:
CI Run: true
Git Hash: fcb5f3c664b293c7a196c9809a33714427804d40
Build Cause: TIMERTRIGGER
Build Time: 2015-03-24 03:25:01 (1427167501)
Build Tag: jenkins-docker centos_base-20
Actions:
START: not set
UPDATE: not set
VALIDATE: not set
Metadata for image rbldnsd
Names:
Project Name: rbldnsd
Image Name: ripienaar/rbldnsd
Image Tag Names: hub.my.net/ripienaar/rbldnsd
Build Info:
CI Run: true
Git Hash: e1b0a445744fec5e584919711cafd8f4cebdee0e
Build Cause: TIMERTRIGGER
Build Time: 2015-03-30 06:02:10 (1427691730)
Build Tag: jenkins-docker rbldnsd-55
Actions:
START: /srv/support/bin/start.sh
UPDATE: /srv/support/bin/update.sh
VALIDATE: /srv/support/bin/validate.sh |
% docker exec -ti rbldnsd container --examine
Container first started at 2015-03-30 05:02:37 +0000 (1427691757)
Container management methods:
Container supports START method using command /srv/support/bin/start.sh
Container supports UPDATE method using command /srv/support/bin/update.sh
Container supports VALIDATE method using command /srv/support/bin/validate.sh
Metadata for image centos_base
Names:
Project Name: centos_base
Image Name: ripienaar/centos_base
Image Tag Names: hub.my.net/ripienaar/centos_base
Build Info:
CI Run: true
Git Hash: fcb5f3c664b293c7a196c9809a33714427804d40
Build Cause: TIMERTRIGGER
Build Time: 2015-03-24 03:25:01 (1427167501)
Build Tag: jenkins-docker centos_base-20
Actions:
START: not set
UPDATE: not set
VALIDATE: not set
Metadata for image rbldnsd
Names:
Project Name: rbldnsd
Image Name: ripienaar/rbldnsd
Image Tag Names: hub.my.net/ripienaar/rbldnsd
Build Info:
CI Run: true
Git Hash: e1b0a445744fec5e584919711cafd8f4cebdee0e
Build Cause: TIMERTRIGGER
Build Time: 2015-03-30 06:02:10 (1427691730)
Build Tag: jenkins-docker rbldnsd-55
Actions:
START: /srv/support/bin/start.sh
UPDATE: /srv/support/bin/update.sh
VALIDATE: /srv/support/bin/validate.sh
This is the same information as above but also showing the ancestor of this rbldnsd image – the centos_base image. I can see when they were built, why, what hashes of the repositories and I can see how I can interact with these containers. From here I can audit or manage their life cycle quite easily.
I’d like to add to this a bunch of run-time information like when was it deployed, why, to what node etc and will leverage the docker metadata when that becomes available or hack something up with ENV variables.
Solving this problem has been key to getting to grips of the operational concerns I had with Docker and feeling I can get back to the level of maturity I had with packages.
Management
You can see from above that the metadata supports specifying START, UPDATE and VALIDATE actions. Future ones might be MONITOR and METRICS.
UPDATE requires some explaining. Of course the trend is toward immutable infrastructure where every change is a rebuild and this is a pretty good approach. I host things like a DNS based RBL and these tend to update all the time, I’d like to do so quicker and with less resource usage than a full rebuild and redeploy – but without ending up in a place where a rebuild loses my changes.
So the typical pattern I do this with is to make the data directories for these images be git checkouts using deploy keys on my git server. The build process will always take latest git and the update process will fetch latest git and reload the running config. This is a good middle ground somewhere between immutability and rapid change. I rebuild and redeploy all my containers every night so this covers the few hours in between.
Here’s my DNS server:
% sudo docker exec bind container --update
>> Fetching latest git checkout
From https://git.devco.net/ripienaar/docker_bind
* branch master -> FETCH_HEAD
Already up-to-date.
>> Validating configuration
>> Checking named.conf syntax in master mode
>> Checking named.conf syntax in slave mode
>> Checking zones..
>> Reloading name server
server reload successful |
% sudo docker exec bind container --update
>> Fetching latest git checkout
From https://git.devco.net/ripienaar/docker_bind
* branch master -> FETCH_HEAD
Already up-to-date.
>> Validating configuration
>> Checking named.conf syntax in master mode
>> Checking named.conf syntax in slave mode
>> Checking zones..
>> Reloading name server
server reload successful
There were no updates but you can see it would fetch the latest, validate it passes inspection and then reload the server if everything is ok. And here is the main part of the script implementing this action:
echo ">> Fetching latest git checkout"
git pull origin master
echo ">> Validating configuration"
container --validate
echo ">> Reloading name server"
rndc reload |
echo ">> Fetching latest git checkout"
git pull origin master
echo ">> Validating configuration"
container --validate
echo ">> Reloading name server"
rndc reload
This way I just need to orchestrate these standard container –update execs – webhooks does this in my case.
VALIDATE is interesting too, in this case validate uses the usual named-checkconf and named-checkzone commands to check the incoming config files but my more recent containers use serverspec and infrataster to validate the full end to end functionality of a running container.
% sudo docker exec -ti rbldnsd container --validate
.............................
Finished in 6.86 seconds (files took 0.39762 seconds to load)
29 examples, 0 failures |
% sudo docker exec -ti rbldnsd container --validate
.............................
Finished in 6.86 seconds (files took 0.39762 seconds to load)
29 examples, 0 failures
My dev process revolves around this like TDD would, my build process will run these steps end of every build in a running instance of the container, my deploy process runs this post deploy of anything it deploys. Operationally if anything is not working right my first port of call is just this command, it often gets me right down to the part that went wrong – if I have good tests that is, otherwise this is feedback to the dev cycle leading to improved tests. I mentioned I rebuild and redeploy the entire infrastructure daily – it’s exactly the investment in these tests that means I can do so while getting a good nights sleep.
Monitoring will likewise be extended around standardised introspectible commands so that a single method can be made to extract status and metric information out of any container built on this method.
Outcome
I’m pretty happy with where this got me, I found it much easier to build some tooling around containers given rich metadata and standardised interaction models. I kind of hoped this was what I would get from Docker itself but it’s either too early or what it provides is too low level – understandable as from it’s perspective it would want to avoid being too prescriptive or have limited sets of data it supports on limited operating systems. I think though as a team who want to build and deploy a solid infrastructure on Docker you need to invest in something along these lines.
Thus my containers now do not just contain their files and dependencies but more and more their operational life cycle is part of the container. Containers can be asked for their health, they can update themselves and eventually emit detailed reusable metrics and statuses. The API to do all of this is standardised and I can run this anywhere with confidence gained from having these introspective abilities and metadata anywhere. Like the huge benefit I got from an improved workflow I find this embedded operational life cycle is equally large and something that I found hard to achieve in my old traditional CM based approach.
I think PaaS systems need to get a bit more of this kind of thing in their pipelines, I’d like to be able to ask my PaaS to just run my validate steps regularly or on demand. Or have standardised monitoring status and metrics output so that the likes of Datadog etc can deliver agents that provide in depth application monitoring without configuration by just sitting in a container next to a set of these containers. Today the state of the art for PaaS health checks seem to be to just hit the exposed port, but real life management of services is much more intricate than that. If they had that I could adopt one of those and spare myself a lot of pain.
For now though this is what my systems will do and hopefully some of the ideas become generally accepted.
by R.I. Pienaar | Feb 21, 2015 | Code, Uncategorized
Been a while since I posted here about my travlrmap web app, I’ve been out of town the whole of February – first to Config Management Camp and then on holiday to Spain and Andorra.
I released version 1.5.0 last night which brought a fair few tweaks and changes like updating to latest Bootstrap, improved Ruby 1.9.3 UTF-8 support, give it a visual spruce up using the Map Icons Collection and gallery support.
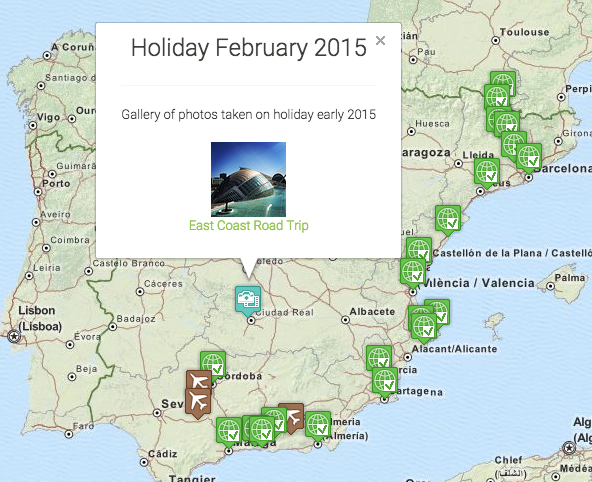
I take a lot of photos and of course often these photos coincide with travels. I wanted to make it easy to put my travels and photos on the same map so have started adding a gallery ability to the map app. For now it’s very simplistic, it makes a point with a custom HTML template that just opens a new tab to the Flickr slideshow feature. This is not what I am after exactly, ideally when you click view gallery it would just open a overlay above the map and show the gallery with escape to close – that would take you right back to the map. There re some bootstrap plugins for this but they all seem to have some pain points so that’s not done now.
Today there’s only Flickr support and a gallery takes a spec like :gallery: flickr,user=ripienaar,set=12345 and from there it renders the Flickr set. Once I get the style of popup gallery figured out I’ll make that pluggable through gems so other photo gallery tools can be supported with plugins.
As you can see from above the trip to Spain was a Road Trip, I kept GPX tracks of almost the entire trip and will be adding support to show those on the map and render them. Again they’ll appear as a point just like galleries and clicking on them will show their details like a map view of the route and stats. This should be the aim for the 1.6.0 release hopefully.
by R.I. Pienaar | Jan 15, 2015 | Uncategorized
I’ve been with Linode since almost their day one, I’ve never had reason to complain. Over the years they have upgraded the various machines I’ve had for free, I’ve had machines with near 1000 days uptime with them, their control panel is great, their support is great. They have a mature set of value added services around the core like load balancers, backups etc. I’ve recommended them to 10s of businesses and friends who are all hosted there. In total over the years I’ve probably had or been involved in over a thousand Linode VMs.
This is changing though, I recently moved 4 machines to their London datacenter and they have all been locking up randomly. You get helpful notices saying something like “Our administrators have detected an issue affecting the physical hardware your Linode resides on.” and on pushing the matter I got:
I apologize for the amount of hardware issues that you have had to deal with lately. After viewing your account, their have been quite a few hardware issues in the past few months. Unfortunately, we cannot easily predict when hardware issues may occur, but I can assure you that our administrators do everything possible to address and eliminate the issues as they do come up.
If you do continue to have issues on this host, we would be happy to migrate your Linode to a new host in order to see if that alleviates the issues going forward.
Which is something I can understand, yes hardware fail randomly, unpredictably etc. I’m a systems guy, we’ve all been on the wrong end of this stick. But here’s the thing, in the longer than 10 years I’ve been with Linode and had customers with Linode this is something that happens very infrequently, my recent experience is completely off the scales bad. It’s clear there’s a problem, something has to be done. You expect your ISP to do something and to be transparent about it.
I have other machines at Linode London that were not all moved there on the same day and they are fine. All the machines I moved there on the same day recently have this problem. I can’t comment on how Linode allocate VMs to hosts but it seems to me there might be a bad batch of hardware or something along these lines. This is all fine, bad things happen – it’s not like Linode manufactures the hardware – I don’t mind that it’s just realistic. What I do mind is the vague non answers to the problem, I can move all my machines around and play russian roulette till it works. Or Linode can own up to having a problem and properly investigate and do something about it while being transparent with their customers.
Their community support team reached out almost a month ago after I said something on Twitter with “I’ve been chatting with our team about the hardware issues you’ve experienced these last few months trying to get more information, and will follow up with you as soon as I have something for you” I replied saying I am moving machines one by one soon as they fail but never heard back again. So I can’t really continue to support them in the face of this.
When my Yum mirror and Git repo failed recently I decided it’s time to try Digital Ocean since that seems to be what all the hipsters are on about. After a few weeks I’ve decided they are not for me.
- Their service is pretty barebones which is fine in general – and I was warned about this on Twitter. But they do not even provide local resolvers, the machines are set up to use Google resolvers out of the box. This is just not ok at all. Support says indeed they don’t and will pass on my feedback. Yes I can run a local cache on the machine. Why should every one of thousands of VMs need this extra overhead in terms of config, monitoring, management, security etc when the ISP can provide reliable resolvers like every other ISP?
- Their london IP addresses at some point had incorrect contact details, or were assigned to a different DC or something. But geoip databases have them being in the US which makes all sorts of things not work well. The IP whois seems fine now, but will take time to get reflected in all the geoip databases – quite annoying.
- Their support system do not seem to send emails. I assume I just missed some click box somewhere in their dashboard because it seems inconceivable that people sit and poll the web UI while they wait for feedback from support.
On the email thing – my anti spam could have killed them as well I guess, I did not investigate this too deep because after the resolver situation became clear it seemed like wasted effort to dig into that as the resolver issue was the nail in the coffin regardless.
Technically the machine was fine – it was fast, connectivity good, IPv6 reliable etc. But for the reasons above I am trying someone else. BigV.io contacted me to try them, so giving that a go and will see how it look.
by R.I. Pienaar | Dec 9, 2013 | Code, Uncategorized
My recent post about using Hiera data in modules has had a great level of discussion already, several thousand blog views, comments, tweets and private messages on IRC. Thanks for the support and encouragement – it’s clear this is a very important topic.
I want to expand on yesterdays post by giving some background information on the underlying motivations that caused me to write this feature and why having it as a forge module is highly undesirable but the only current option.
At the heart of this discussion is the params.pp pattern and general problems with it. To recap, the basic idea is to embed all your default data into a file params.pp typically in huge case statements and then reference this data as default. Some examples of this are the puppetlabs-ntp module, the Beginners Guide to Modules and the example I had in the previous post that I’ll reproduce below:
# ntp/manifests/init.pp
class ntp (
# allow for overrides using resource syntax or data bindings
$config = $ntp::params::config,
$keys_file = $ntp::params::keys_file
) inherits ntp::params {
# validate values supplied
validate_absolute_path($config)
validate_absolute_path($keys_file)
# optionally derive new data from supplied data
# use data
file{$config:
....
}
} |
# ntp/manifests/init.pp
class ntp (
# allow for overrides using resource syntax or data bindings
$config = $ntp::params::config,
$keys_file = $ntp::params::keys_file
) inherits ntp::params {
# validate values supplied
validate_absolute_path($config)
validate_absolute_path($keys_file)
# optionally derive new data from supplied data
# use data
file{$config:
....
}
}
# ntp/manifests/params.pp
class ntp::params {
# set OS specific values
case $::osfamily {
'AIX': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp.keys'
}
'Debian': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp/keys'
}
'RedHat': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp/keys'
}
default: {
fail("The ${module_name} module is not supported on an ${::osfamily} based system.")
}
}
} |
# ntp/manifests/params.pp
class ntp::params {
# set OS specific values
case $::osfamily {
'AIX': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp.keys'
}
'Debian': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp/keys'
}
'RedHat': {
$config = "/etc/ntp.conf"
$keys_file = '/etc/ntp/keys'
}
default: {
fail("The ${module_name} module is not supported on an ${::osfamily} based system.")
}
}
}
Now today as Puppet stands this is pretty much the best we can hope for. This achieves a lot of useful things:
- The data that provides OS support is contained and separate
- You can override it using resource style syntax or Puppet 3 data bindings
- The data provided using any means are validated
- New data can be derived by combining supplied or default data
You can now stick this module on the forge and users can use it, it supports many Operating Systems and pretty much works on any Puppet going back quite a way. These are all good things.
The list above also demonstrates the main purpose for having data in a module – different OS/environment support, allowing users to supply their own data, validation and to transmogrify the data. The params.pp pattern achieves all of this.
So what’s the problem then?
The problem is: the data is in the code. In the pre extlookup and Hiera days we put our site data in a case statements or inheritance trees or node data or any of number of different solutions. These all solved the basic problem – our site got configured and our boxes got built just like the params.pp pattern solves the basic problem. But we wanted more, we wanted our data separate from our code. Not only did it seem natural because almost every other known programming language supports and embrace this but as Puppet users we wanted a number of things:
- Less logic, syntax, punctuation and “programming” and more just files that look a whole lot like configuration
- Better layering than inheritance and other tools at our disposal allowed. We want to structure our configuration like we do our DCs and environments and other components – these form a natural series of layered hierarchies.
- We do not want to change code when we want to use it, we want to configure that code to behave according to our site needs. In a CM world data is configuration.
- If we’re in a environment that do not let us open source our work or contribute to open source repositories we do not want to be forced to fork and modify open source code just to use it in our environments. We want to configure the code. Compliance needs should not force us to solve every problem in house.
- We want to plug into existing data sources like LDAP or be able to create self service portals for our users to supply this configuration data. But we do not want to change our manifests to achieve this.
- We do not want to be experts at using source control systems. We use them, we love them and agree they are needed. But like everything less is more. Simple is better. A small simple workflow we can manage at 2am is better than a complex one.
- We want systems we can reason about. A system that takes configuration in the form of data trumps one that needs programming to change its behaviour
- Above all we want a system that’s designed with our use cases in mind. Our User Experience needs are different from programmers. Our data needs are different and hugely complex. Our CM system must both guide in its design and be compatible with our existing approaches. We do not want to have to write our own external node data sources simply because our language do not provide solid solutions to this common problem.
I created Hiera with these items in mind after years of talking to probably 1000+ users and iterating on extlookup in order to keep pace with the Puppet language gaining support for modern constructs like Hashes. True it’s not a perfect solution to all these points – transparency of data origin to name but one – but there are approaches to make small improvements to achieve these and it does solve a high % of the above problems.
Over time Hiera has gained a tremendous following – it’s now the de facto standard to solving the problem of site configuration data largely because it’s pragmatic, simple and designed to suit the task at hand. In recognition of this I donated the code to Puppet Labs and to their credit they integrated it as a default prerequisite and created the data binding systems. The elephant in the room is our modules though.
We want to share our modules with other users. To do this we need to support many operating systems. To do this we need to create a lot of data in the modules. We can’t use Hiera to do this in a portable fashion because the module system needs improvement. So we’re stuck in the proverbial dark ages by embedding our data in code and gaining none of the advantages Hiera brings to site data.
Now we have a few options open to us. We can just suck it up and keep writing params.pp files gaining none of the above advantages that Hiera brings. This is not great and the puppetlabs-ntp module example I cited shows why. We can come up with ever more elaborate ways to wrap and extend and override the data provided in a params.pp or even far out ideas like having the data binding system query the params.pp data directly. In other words we can pander to the status quo, we can assume we cannot improve the system instead we have to iterate on an inherently bad idea. The alternative is to improve Puppet.
Every time the question of params.pp comes up the answer seems to be how to improve how we embed data in the code. This is absolutely the wrong answer. The answer should be how do we improve Puppet so that we do not have to embed data in code. We know people want this, the popularity and wide adoption of Hiera has shown that they do. The core advantages of Hiera might not be well understood by all but the userbase do understand and treasure the gains they get from using it.
Our task is to support the community in the investment they made in Hiera. We should not be rewriting it in a non backwards compatible way throwing away past learnings simply because we do not want to understand how we got here. We should be iterating with small additions and rounding out this feature as one solid ever present data system that every user of Puppet can rely on being present on every Puppet system.
Hiera adoption has reached critical mass, it’s now the solution to the problem. This is a great and historical moment for the Puppet Community, to rewrite it or throw it away or propose orthogonal solutions to this problem space is to do a great disservice to the community and the Puppet product as a whole.
Towards this I created a Hiera backend that goes a way to resolve this in a way thats a natural progression of the design of Hiera. It improves the core features provided by Puppet in a way that will allow better patterns than the current params.pp one to be created that will in the long run greatly improve the module writing and sharing experience. This is what my previous blog post introduce, a way forward from the current params.pp situation.
Now by rights a solution to this problem belong in Puppet core. A Puppet Forge dependant module just to get this ability, especially one not maintained by Puppet Labs, especially one that monkey patches its way into the system is not desirable at all. This is why the code was a PR first. The only alternatives are to wait in the dark – numerous queries by many members of the community to the Puppet product owner has yielded only vague statements of intent or outcome. Or we can take it on our hands to improve the system.
So I hope the community will support me in using this module and work with me to come up with better patterns to replace the params.pp ones. Iterating on and improving the system as a whole rather than just suck up the status quo and not move forward.
