by R.I. Pienaar | Jun 30, 2007 | Front Page
This is just a quick heads-up that I am moving this site and most of my services that I offer people to a new server this means for a while things will be odd.
The new machine is still with Blackcat Networks who I never hesitate to recommend to anyone. The new machine was purchased from DNUK who specialize in Linux servers, their service were great and managed to build me a machine that would fit into 0.5Amp power usage easily.
The final spec is a AMD X2 3800+, 2 x 250GB drives and 2GB memory, all happily running at around 0.4Amp. The old server is a Dell 1550 1Ghz PIII, so this will be a very welcome upgrade.
by R.I. Pienaar | Jun 23, 2007 | Usefull Things
I’ve had the miss-fortune of configuring IPSEC on many FreeBSD machines and other devices in the past and in all cases it’s been a pain, as a result I’ve been putting off securing connections between 3 machines that I knew needed IPSEC.
Last night I figured I may as well start looking at what is involved in building a star topology between the three hosts where comms between each node and each other node is encrypted. Turns out it could not possibly have been simpler.
This is well documented in the RedHat docs – RHEL 3, RHEL 4, RHEL 5 – but it’s worth repeating because it really is clean and simple and elegant.
Being that these are point-to-point tunnels it makes a lot of sense to see the connections as new network cards and this is the approach redhat took, simply create /etc/sysconfig/network-scripts/ifcfg-ipsecX files where X is any number. This is a sample:
DST=x.x.x.x
TYPE=IPSEC
ONBOOT=yes
IKE_METHOD=PSK |
DST=x.x.x.x
TYPE=IPSEC
ONBOOT=yes
IKE_METHOD=PSK
And do the same on your other host. Now create a pre-shared key in /etc/sysconfig/network-scripts/keys-ipsecX with file mode 600:
This key has to be the same on both hosts, run ifup ipsecX and it should negotiate, check /var/log/messages for diagnostics.
It is that easy, you can use tcpdump to verify that all is working good.
Under the covers the redhat scripts still use racoon and all the standard stuff, it creates files in /etc/racoon and you can use tools such as setkey etc to diagnose problems.
This is a simple p2p VPN, the RedHat docs shows how to do it on your gateway device – it’s as simple.
by R.I. Pienaar | Jun 2, 2007 | Code
I’ve been doing a whole lot of programming recently and even getting into doing some MySQL stored procedure and trigger programming. I got a copy of the excellent book MySQL Stored Procedure Programming and can recommend it to anyone keen to get information on the subject.
Usually when dealing with errors in stored procedures or triggers you define a handler for the MySQL error code and either continue – and presumably do something to handle the exception – or exit with an error. When doing an UPDATE with a WHERE clause that does not match any data though no error gets thrown, it just doesn’t do anything.
So I tried to come across some samples of how to get the affected row count but came up short – there are very few online resources that I found about MySQL stored procedures in general. So here is a solution for a simple trigger that updates a table when new data arrives in another.
DELIMITER $$
CREATE TRIGGER trg_update_latest_on_email_stats
AFTER INSERT ON email_stats
FOR each row
BEGIN
DECLARE l_rows INT DEFAULT 0;
UPDATE server_stats SET last_email_time = NEW.time
WHERE server_name = NEW.server_name;
/* how many rows did we affect? */
SELECT ROW_COUNT() INTO l_rows;
/* If we didn't update any rows, then insert new data */
IF (l_rows = 0) THEN
INSERT INTO server_stats (server_name, last_email_time)
VALUES (NEW.server_name, NEW.time);
END IF;
END $$
That’s it, pretty simple stuff.
Data comes in, the trigger fires but if there is no data there nothing happens, so it inserts some data and future updates will pass.
I could have used the REPLACE function for simpler code, but my solution should be faster which is key when using trigggers.
by R.I. Pienaar | Apr 8, 2007 | Front Page
This is part 3 of my series of posts on the general usability of Google Apps for Domains as a hosting service for email. This one really speaks for itself so I’ll keep it short.
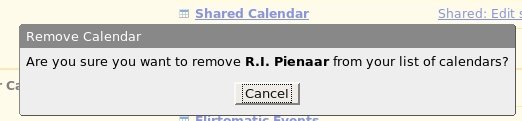
It’s a bit like those joke Windows error messages that does the rounds.
by R.I. Pienaar | Apr 2, 2007 | Front Page
This is the 2nd in a series of posts about Google Apps for Domains, I’ve been evaluating it for a while. Today I’ll focus a bit on the XML feeds that Google Calendar outputs as a means of integrating it into other applications.
It basically provides 2 types of XML – a private and a public one. The public one only works if you share the cal publicly and the other is for your own use to pull into apps of your own. Each calendar should have a private one.
This sounds very interesting, so what’s the problem? Well there are some inconsistencies. On my two domains, the one has private URLs on the main calendar the other doesn’t have the option at all. So this means my primary calendar doesn’t have a XML feed unless I share it publicly.
GCal also has a feature that mails you a short daily agenda, much like what you see if you hit the Agenda button. Problem is the agenda mail function ONLY reads from your primary calendar, it does not include events from any subscribed calendars etc. This means that one of the biggest selling points of Google for Domains is crippled, if you share calendars you can’t use them even in the rudimentary tools provided.
I can’t use my primary private calendar with XML feeds, and I can only get events mailed from the primary calendar. Why is this a problem? I want to use the shared calendars with people I work with, that’s one of the major reasons to use Apps for Domains.
On my iCal calendars I had a RSS feed that I’d pull into some perl code to generate agendas. I resigned myself to the fact that I’d need to write one myself again now for GCal and wanted to use the XML feeds. I can’t pull events into my primary calendar – it doesn’t have private feeds – so I had to create a new cal and use that – completely invalidating the in UI agenda function. I also can’t delete the primary function, the option is grey’d out.
Back to the feeds, by default the data you’ll get in a feed looks like this for recurring events:
<?xml version='1.0' encoding='UTF-8'?>
<entry xmlns='http://www.w3.org/2005/Atom'
xmlns:gd='http://schemas.google.com/g/2005'
xmlns:gCal='http://schemas.google.com/gCal/2005'>
<id>removed</id>
<published>2006-09-04T18:45:41.000Z</published>
<updated>2007-03-15T23:50:18.000Z</updated>
<category scheme='http://schemas.google.com/g/2005#kind'
term='http://schemas.google.com/g/2005#event'></category>
<title type='text'>Cleaners</title>
<summary type='html'>Recurring Event<br>
First start: 2006-09-01 11:30:00 BST <br>
Duration: 3600 <br>
Who: Shared Calendar <br>
Event Status: tentative</summary>
<content type='text'>Recurring Event<br>
First start: 2006-09-01 11:30:00 BST <br>
Duration: 3600 <br>
Who: Shared Calendar <br>
Event Status: tentative</content>
<link rel='alternate' type='text/html' href='removed' title='alternate'>
</link>
<link rel='self' type='application/atom+xml' href='removed'>
</link>
<author>
<name>R.I. Pienaar</name>
<email>rip@removed</email>
</author>
<gCal:sendEventNotifications value='true'></gCal:sendEventNotifications>
</entry>
Have a good look at that, this is the default feed output, it shows you details for a recurring event – when it was first created and how long it runs for. There is not enough information here for a human to actually figure out when this event is for, they do not give you any information about the schedule, this event may recur once a year, once a day, once a month you just don’t have any idea. You’ll see later that they have all the ability already to make this useful and user friendly, they just didn’t bother.
The devs in the Google Support Groups say the default feed is for ease of reading by a human and not for machines, for machines you need to use the full feed query format . This lets you do all sorts of good queries for feeds, date ranges and all sorts of things.
Not only is the default feed not machine friendly, no human can figure out what a recurring event is, when it runs etc, as a data feed the default GCal feed is completely useless to everyone.
Using the full feed I now have a daily mail that I have to schedule on my own server to produce a daily agenda, something like this:
Things to do TODAY - Monday, 02 April 2007
No events.
Things to do TOMORROW - Tuesday, 03 April 2007
Test Event
Things to do next 7 days:
Friday Cleaners
Friday Good Friday
Saturday Rebecca Birthday Party
Monday Easter Monday
I had to write this myself using perl and had to go and do this using the full feeds, interestingly enough the full feed has options to expand the recurring events into a single entry, so for instance my Cleaners entry in the agenda above is the same recurring event from the XML earlier. So clearly their backend has the ability to turn the nasty useless recurring event format into something totally human readable and useful, they just chose not to make the default feeds a useful feature.
The calendar has a lot of other questionable features and limitations, it really is a load of compromises, bugs and half baked features cobbled together in something that does not really work as a proper shared calendar environment like a paying customer would expect. And these limitations is not limited to the free versions, they are exactly the same in the paying version. I’d say anyone serious about shared calendar apps or about 3rd party integration should really give GCal and Apps for Domains a miss.
