by R.I. Pienaar | Jul 3, 2010 | Code
A very typical scenario I come across on many sites is the requirement to monitor something like Puppet across 100s or 1000s of machines.
The typical approaches are to add perhaps a central check on your puppet master or to check using NRPE or NSCA on every node. For this example the option exist to easily check on the master and get one check but that isn’t always easily achievable.
Think for example about monitoring mail queues on all your machines to make sure things like root mail isn’t getting stuck. In those cases you are forced to do per node checks which inevitably result in huge notification storms in the event that your mail server was down and not receiving the mail from the many nodes.
MCollective has had a plugin that can run NRPE commands for a long time, I’ve now added a nagios plugin using this agent to combine results from many hosts.
Sticking with the Puppet example, here are my needs:
- I want to know if anywhere some puppet machine isn’t successfully doing runs.
- I want to be able to do puppetd –disable and not get alerts for those machines.
- I do not want to change any configs when I am adding new machines, it should just work.
- I want the ability to do monitoring on subsets of machines on different probes
This is a pretty painful set of requirements for nagios on its own to achieve. Easy with the help of MCollective.
Ultimately, I just want this:
OK: 42 WARNING: 0 CRITICAL: 0 UNKNOWN: 0 |
OK: 42 WARNING: 0 CRITICAL: 0 UNKNOWN: 0
Meaning 42 machines – only ones currently enabled – are all running happily.
The NRPE Check
We put the NRPE logic on every node. A simple check command in /etc/nagios/nrpe.d/check_puppet_run.cfg:
command[check_puppet_run]=/usr/lib/nagios/plugins/check_file_age -f /var/lib/puppet/state/state.yaml -w 5400 -c 7200 |
command[check_puppet_run]=/usr/lib/nagios/plugins/check_file_age -f /var/lib/puppet/state/state.yaml -w 5400 -c 7200
In my case I just want to know there are successful runs happening, if I wanted to know the code is actually compiling correctly I’d monitor the local cache age and size.
Determining if Puppet is enabled or not
Currently this is a bit hacky, I’ve filed tickets with Puppet Labs to improve this. The way to determine if puppet is disabled is to check if the lock file exist and if its 0 bytes. If it’s not zero bytes it means a puppetd is currently doing a run – there will be a pid in it. Or the puppetd crashed and there’s a stale pid preventing other runs.
To automate this and integrate into MCollective I’ve made a fact puppet_enabled. We’ll use this in MCollective discovery to only monitor machines that are enabled. Get this onto all your nodes perhaps using Plugins in Modules.
The MCollective Agent
You want to deploy the MCollective NRPE Agent to all your nodes, once you’ve got it right you can test it easily using something like this:
% mc-nrpe -W puppet_enabled=1 check_puppet_run
* [ ============================================================> ] 47 / 47
Finished processing 47 / 47 hosts in 395.51 ms
OK: 47
WARNING: 0
CRITICAL: 0
UNKNOWN: 0 |
% mc-nrpe -W puppet_enabled=1 check_puppet_run
* [ ============================================================> ] 47 / 47
Finished processing 47 / 47 hosts in 395.51 ms
OK: 47
WARNING: 0
CRITICAL: 0
UNKNOWN: 0
Note we’re restricting the run to only enabled hosts.
Integrating into Nagios
The last step is to add this to nagios. I create SSL certs and a specific client configuration for Nagios and put these in it’s home directory.
The check-mc-nrpe plugin works best with Nagios 3 as it will return subsequent lines of output indicating which machines are in what state so you get the details hidden behind the aggregation in alerts. It also outputs performance data for total node, each status and also how long it took to do the check.
The nagios command would be something like this:
define command{
command_name check_mc_nrpe
command_line /usr/sbin/check-mc-nrpe --config /var/log/nagios/.mcollective/client.cfg -W $ARG1$ $ARG2$
} |
define command{
command_name check_mc_nrpe
command_line /usr/sbin/check-mc-nrpe --config /var/log/nagios/.mcollective/client.cfg -W $ARG1$ $ARG2$
}
And finally we need to make a service:
define service{
host_name monitor1
service_description mc_puppet-run
use generic-service
check_command check_mc_nrpe!puppet_enabled=1!check_puppet_run
notification_period awakehours
contact_groups sysadmin
} |
define service{
host_name monitor1
service_description mc_puppet-run
use generic-service
check_command check_mc_nrpe!puppet_enabled=1!check_puppet_run
notification_period awakehours
contact_groups sysadmin
}
Here are a few other command examples I use:
All machines with my Puppet class “pki”, check the age of certs:
check_command check_mc_nrpe!pki!check_pki |
check_command check_mc_nrpe!pki!check_pki
All machines with my Puppet class “bacula::node”, make sure the FD is running:
check_command check_mc_nrpe!bacula::node!check_fd |
check_command check_mc_nrpe!bacula::node!check_fd
…and that they were backed up:
check_command check_mc_nrpe!bacula::node!check_bacula_main |
check_command check_mc_nrpe!bacula::node!check_bacula_main
Using this I removed 100s of checks from my monitoring platform, saving on resources and making sure I can do my critical monitor tasks better.
Depending on the quality of your monitoring system you might even get a graph showing the details hidden behind the aggregation:
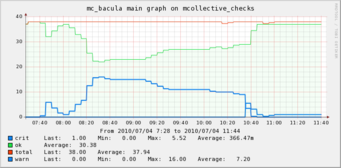
The above is a graph showing a series of servers where the backup ran later than usual, I had 2 alerts only, would have had more than 30 before aggregation.
Restrictions for Probes
The last remaining requirement I had was to be able to do checks on different probes and restrict them. My Collective is one big one spread all over the world which means sometimes things are a bit slow discovery wise.
So I have many nagios servers doing local checks. Using MCollective discovery I can now easily restrict checks, for example If I only wanted to check machines in the USA and I had a fact country I only have to change my command line in the service declaration:
check_command check_mc_nrpe!puppet_enabled=1 country=us!check_puppet_run |
check_command check_mc_nrpe!puppet_enabled=1 country=us!check_puppet_run
This will then via MCollective discovery just monitor machines in the US.
What to monitor this way
As this style of monitoring is done using Discovery you would need to think carefully about what you monitor this way. It’s totally conceivable that if a node is under high CPU load that it wont respond to discovery commands in time, and so wont get monitored!
You would then for example not want to monitor things like load averages or really critical services this way, but we all have a lot of peripheral things like zombie process counts and a lot of other places where aggregation makes a lot of sense, in those cases by all means consider this approach.
by R.I. Pienaar | Jun 27, 2010 | Code
I’ve recorded a screencast that walks you through the process of developing a SimpleRPC Agent, give it a DDL and also a simple client to communicate with it.
The tutorial creates a small echo agent that takes input and return it unmodified. It validates that you are sending a string and has a sample of dealing with intermittent failure.
Once you’ve watched this, or even during, you can use the following links are reference material: Writing Agents, Data Definition Language and Writing Clients.
You can view it directly on blip.tv which will hopefully be better quality.
I used a few VIM Snippets during the demo to boilerplate the agent and DDL, you’ll find these in the tarball for the upcoming 0.4.7 release in the ext/vim directory, they are already on GitHub too.
by R.I. Pienaar | Jun 14, 2010 | Code
I’ve had two successive Marionette Collective releases recently, I was hoping to have one big one but I was waiting for the Stomp maintainers to do a release and it was taking a while.
These two releases are both major feature releases covering major feature sets. See lower down for a breakdown of it all.
We’re nearing feature completeness for the SimpleRPC layer as I am adding a number of features of interest to Enterprise and Large users especially around security and web UIs.
Once we’re at the end of this cycle I’ll do a 1.0.0 release and then from there move onto the next major feature cycle. The next cycle will focus on queuing long running tasks, background scheduling, future scheduling of tasks and a lot of related work. I posted some detail about these plans to the list recently.
Over the new few days or weeks I’ll do a number of Screencasts exploring some of these new features in depth, for now the list of what’s new:
Security
Connectivity
We can use Ruby Gem Stomp 1.1.6 which brings a lot of enhancements:
-
Connection pools for failover between multiple ActiveMQs
- Lots of tunables about the connection pools such as retry frequencies etc
- SSL TLS between node and ActiveMQ
Writing Web and Dynamic UIs
- A DDL that describes agents, inputs and outputs:
- Creates auto generated documentation
- Can be used to auto generate user interfaces
- The client library will only make requests that validate against the DDL
- In future input validations will move into the DDL and will be done automatically for you
- Web UI’s can bypass or do their own discovery and use the DDL to auto generate user interfaces
Usability
-
Fire-and-Forget style requests, for when you just want something done but do not care about results, these requests are very quick as they do not do any discovery.
- Agents can now be reloaded without restarting the daemon
- A new mc-inventory tool that can be used to view facts, agents and classes for a node
- Many UI enhancements to the CLI tools
by R.I. Pienaar | Apr 14, 2010 | Code
I retweeted this on twitter, but it’s just too good to not show. Over at rottenbytes.com Nicolas is showing some proof of concept code he wrote with MCollective that monitors the load on his dom0 machines and initiate live migrations of virtual machines to less loaded servers.
This is the kind of crazy functionality I wanted to enable with MCollective and it makes me very glad to see this kind of thing. The server side and client code combined is only 230 lines – very very impressive.
This is a part of what VMWare DRS does Nico has some ideas to add other sexy features as well as this was just a proof of concept. The logic for what to base migrations on will be driven by a small DSL for example.
I asked him how long it took to knock this together: time taken to get acquainted with MCollective combined with time to write the agent and client was only 2 days, that’s very impressive. He already knew Ruby well though 🙂 And has a Ruby gem to integrate with Xen.
I’m copying the output from his code below, but absolutely head over to his blog to check it out he has the source up there too:
[mordor:~] ./mc-xen-balancer
[+] hypervisor2 : 0.0 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.11 load and 3 slice(s) running
[+] added test1 on hypervisor3 with 0 CPU time (registered 18.4 as a reference)
[+] added test2 on hypervisor3 with 0 CPU time (registered 19.4 as a reference)
[+] added test3 on hypervisor3 with 0 CPU time (registered 18.3 as a reference)
[+] sleeping for 30 seconds
[+] hypervisor2 : 0.0 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.33 load and 3 slice(s) running
[+] updated test1 on hypervisor3 with 0.0 CPU time eaten (registered 18.4 as a reference)
[+] updated test2 on hypervisor3 with 0.0 CPU time eaten (registered 19.4 as a reference)
[+] updated test3 on hypervisor3 with 1.5 CPU time eaten (registered 19.8 as a reference)
[+] sleeping for 30 seconds
[+] hypervisor2 : 0.16 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.33 load and 3 slice(s) running
[+] updated test1 on hypervisor3 with 0.0 CPU time eaten (registered 18.4 as a reference)
[+] updated test2 on hypervisor3 with 0.0 CPU time eaten (registered 19.4 as a reference)
[+] updated test3 on hypervisor3 with 1.7 CPU time eaten (registered 21.5 as a reference)
[+] hypervisor3 has 3 threshold overload
[+] Time to see if we can migrate a VM from hypervisor3
[+] VM key : hypervisor3-test3
[+] Time consumed in a run (interval is 30s) : 1.7
[+] hypervisor2 is a candidate for being a host (step 1 : max VMs)
[+] hypervisor2 is a candidate for being a host (step 2 : max load)
trying to migrate test3 from hypervisor3 to hypervisor2 (10.0.0.2)
Successfully migrated test3 ! |
[mordor:~] ./mc-xen-balancer
[+] hypervisor2 : 0.0 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.11 load and 3 slice(s) running
[+] added test1 on hypervisor3 with 0 CPU time (registered 18.4 as a reference)
[+] added test2 on hypervisor3 with 0 CPU time (registered 19.4 as a reference)
[+] added test3 on hypervisor3 with 0 CPU time (registered 18.3 as a reference)
[+] sleeping for 30 seconds
[+] hypervisor2 : 0.0 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.33 load and 3 slice(s) running
[+] updated test1 on hypervisor3 with 0.0 CPU time eaten (registered 18.4 as a reference)
[+] updated test2 on hypervisor3 with 0.0 CPU time eaten (registered 19.4 as a reference)
[+] updated test3 on hypervisor3 with 1.5 CPU time eaten (registered 19.8 as a reference)
[+] sleeping for 30 seconds
[+] hypervisor2 : 0.16 load and 0 slice(s) running
[+] init/reset load counter for hypervisor2
[+] hypervisor2 has no slices consuming CPU time
[+] hypervisor3 : 1.33 load and 3 slice(s) running
[+] updated test1 on hypervisor3 with 0.0 CPU time eaten (registered 18.4 as a reference)
[+] updated test2 on hypervisor3 with 0.0 CPU time eaten (registered 19.4 as a reference)
[+] updated test3 on hypervisor3 with 1.7 CPU time eaten (registered 21.5 as a reference)
[+] hypervisor3 has 3 threshold overload
[+] Time to see if we can migrate a VM from hypervisor3
[+] VM key : hypervisor3-test3
[+] Time consumed in a run (interval is 30s) : 1.7
[+] hypervisor2 is a candidate for being a host (step 1 : max VMs)
[+] hypervisor2 is a candidate for being a host (step 2 : max load)
trying to migrate test3 from hypervisor3 to hypervisor2 (10.0.0.2)
Successfully migrated test3 !
by R.I. Pienaar | Apr 11, 2010 | Code
Till now The Marionette Collective has relied on your middleware to provide all authorization and authentication for requests. You’re able to restrict certain middleware users from certain agents, but nothing more fine grained.
In many cases you want to provide much finer grain control over who can do what, some cases could be:
- A certain user can only request service restarts on machines with a fact customer=acme
- A user can do any service restart but only on machines that has a certain configuration management class
- You want to deny all users except root from being able to stop services, others can still restart and start them
This kind of thing is required for large infrastructures with lots of admins all working in their own group of machines but perhaps a central NOC need to be able to work on all the machines, you need fine grain control over who can do what and we did not have this will now. It would also be needed if you wanted to give clients control over their own servers but not others.
Version 0.4.5 will have support for this kind of scheme for SimpleRPC agents. We wont provide a authorization plugin out of the box with the core distribution but I’ve made one which will be available as a plugin.
So how would you write an auth plugin, first a typical agent would be:
module MCollective
module Agent
class Service<RPC::Agent
authorized_by :action_policy
# ....
end
end
end |
module MCollective
module Agent
class Service<RPC::Agent
authorized_by :action_policy
# ....
end
end
end
The new authorized_by keyword tells MCollective to use the class MCollective::Util::ActionPolicy to do any authorization on this agent.
The ActionPolicy class can be pretty simple, if it raises any kind of exception the action will be denied.
module MCollective
module Util
class ActionPolicy
def self.authorize(request)
unless request.caller == "uid=500"
raise("You are not allow access to #{request.agent}::#{request.action}")
end
end
end
end
end |
module MCollective
module Util
class ActionPolicy
def self.authorize(request)
unless request.caller == "uid=500"
raise("You are not allow access to #{request.agent}::#{request.action}")
end
end
end
end
end
This simple check will deny all requests from anyone but Unix user id 500.
It’s pretty simple to come up with your own schemes, I wrote one that allows you to make policy files like the one below for the service agent:
policy default deny
allow uid=500 * * *
allow uid=502 status * *
allow uid=600 * customer=acme acme::devserver |
policy default deny
allow uid=500 * * *
allow uid=502 status * *
allow uid=600 * customer=acme acme::devserver
This will allow user 500 to do everything with the service agent. User 502 can get the status of any service on any node. User 600 will be able to do any actions on machines with the fact customer=acme that also has the configuration management class acme::devserver on them. Everything else will be denied.
You can do multiple facts and multiple classes in a simple space separated list. The entire plugin to implement such policy controls was only 120 – heavy commented – lines of code.
I think this is a elegant and easy to use layer that provides a lot of functionality. We might in future pass more information about the caller to the nodes. There’s some limitations, specifically about the source of the caller information being essentially user provided so you need to keep that mind.
As mentioned this will be in MCollective 0.4.5.
