It’s been a while since I posted about Choria and where things are. There are major changes in the pipeline so it’s well overdue a update.
The features mentioned here will become current in the next release cycle – about 2 weeks from now.
New choria module
The current gen Choria modules grew a bit organically and there’s a bit of a confusion between the various modules. I now have a new choria module, it will consume features from the current modules and deprecate them.
On the next release it can manage:
- Choria YUM and APT repos
- Choria Package
- Choria Network Broker
- Choria Federation Broker
- Choria Data Adatpaters
Network Brokers
We have had amazing success with the NATS broker, lightweight, fast, stable. It’s perfect for Choria. While I had a pretty good module to configure it I wanted to create a more singular experience. Towards that there is a new Choria Broker incoming that manages an embedded NATS instance.
To show what I am on about, imagine this is all that is required to configure a cluster of 3 production ready brokers capable of hosting 50k or more Choria managed nodes on modestly specced machines:
plugin.choria.broker_network = true plugin.choria.network.peers = nats://choria1.example.net:4223, nats://choria2.example.net:4223, nats://choria3.example.net:4223 plugin.choria.stats_address = :: |
Of course there is Puppet code to do this for you in choria::broker.
That’s it, start the choria-broker daemon and you’re done – and ready to monitor it using Prometheus. Like before it’s all TLS and all that kinds of good stuff.
Federation Brokers
We had good success with the Ruby Federation Brokers but they also had issues particularly around deployment as we had to deploy many instances of them and they tended to be quite big Ruby processes.
The same choria-broker that hosts the Network Broker will now also host a new Golang based Federation Broker network. Configuration is about the same as before you don’t need to learn new things, you just have to move to the configuration in choria::broker and retire the old ones.
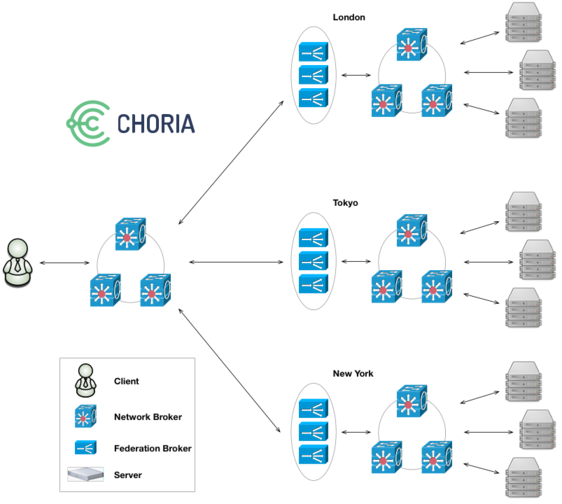
Unlike the past where you had to run 2 or 3 of the Federation Brokers per node you now do not run any additional processes, you just enable the feature in the singular choria-broker, you only get 1 process. Internally each run 10 instances of the Federation Broker, its much more performant and scalable.
Monitoring is done via Prometheus.
Data Adapters
Previously we had all kinds of fairly bad schemes to manage registration in MCollective. The MCollective daemon would make requests to a registration agent, you’d designate one or more nodes as running this agent and so build either a file store, mongodb store etc.
This was fine at small size but soon enough the concurrency in large networks would overwhelm what could realistically be expected from the Agent mechanism to manage.
I’ve often wanted to revisit that but did not know what approach to take. In the years since then the Stream Processing world has exploded with tools like Kafka, NATS Streaming and offerings from GPC, AWS and Azure etc.
Data Adapters are hosted in the Choria Broker and provide stateless, horizontally and vertically scalable Adapters that can take data from Choria and translate and publish them into other systems.

Today I support NATS Streaming and the code is at first-iteration quality, problems I hope to solve with this:
- Very large global scale node metadata ingest
- IoT data ingest – the upcoming Choria Server is embeddable into any Go project and it can exfil data into Stream Processors using this framework
- Asynchronous RPC – replies to requests streaming into Kafka for later processing, more suitable for web apps etc
- Adhoc asynchronous data rewrites – we have had feature requests where person one can make a request but not see replies, they go into Elastic Search
Plugins
After 18 months of trying to get Puppet Inc to let me continue development on the old code base I have finally given up. The plugins are now hosted in their own GitHub Organisation.
I’ve released a number of plugins that were never released under Choria.
I’ve updated all their docs to be Choria specific rather than out dated install docs.
I’ve added Action Policy rules allowing read only actions by default – eg. puppet status will work for anyone, puppet runonce will give access denied.
I’ve started adding Playbooks the first ones are mcollective_agent_puppet::enable, mcollective_agent_puppet::disable and mcollective_agent_puppet::disable_and_wait.
Embeddable Choria
The new Choria Server is embeddable into any Go project. This is not a new area of research for me – this was actually the problem I tried to solve when I first wrote the current gen MCollective, but i never got so far really.
The idea is that if you have some application – like my Prometheus Streams system – where you will run many of a specific daemon each with different properties and areas of responsibility you can make that daemon connect to a Choria network as if it’s a normal Choria Server. The purpose of that is to embed into the daemon it’s life cycle management and provide an external API into this.
The above mentioned Prometheus Streams server for example have a circuit breaker that can start/stop the polling and replication of data:
$ mco rpc prometheus_streams switch -T prometheus
Discovering hosts using the mc method for 2 second(s) .... 1
* [ ============================================================> ] 1 / 1
prom.example.net
Mode: poller
Paused: true
Summary of Mode:
poller = 1
Summary of Paused:
false = 1
Finished processing 1 / 1 hosts in 399.81 ms |
Here I am communicating with the internals of the Go process, they sit in their of Sub Collective, expose facts and RPC endpoints. I can use discovery to find all only nodes in certain modes, with certain jobs etc and perform functions you’d typically do via a REST management interface over a more suitable interface.
Likewise I’ve embedded a Choria Server into IoT systems where it uses the above mentioned Data Adapters to publish temperature and humidity while giving me the ability to extract from those devices data in demand using RPC and do things like in-place upgrades of the running binary on my IoT network.
You can use this today in your own projects and it’s compatible with the Ruby Choria you already run. A full walk through of doing this can be found in the ripienaar/embedded-choria-sample repository.
