Puppet 4 got some new language constructs that let you model multi node applications and it assist with passing information between nodes for you. I recently wrote a open source orchestrator for this stuff which is part of my Choria suite, figured I’ll write up a bit about these multi node applications since they are now useable in open source.
The basic problem this feature solves is about passing details between modules. Lets say you have a LAMP stack, you’re going to have Web Apps that need access to a DB and that DB will have a IP, User, Password etc. Exported resources never worked for this because it’s just stupid to have your DB exporting web resources, there are unlimited amount of web apps and configs, no DB module support this. So something new is needed.
The problem is made worse by the fact that Puppet does not really have something like a Java interface, you can’t say that foo-mysql module implements a standard interface called database so that you can swap out one mysql module for another, they’re all snowflakes. So a intermediate translation layer is needed.
In a way you can say this new feature brings a way to create an interface – lets say SQL – and allows you to hook random modules into both sides of the interface. On one end a database and on the other a webapp. Puppet will then transfer the information across the interface for you, feeding the web app with knowledge of port, user, hosts etc.
LAMP Stack Walkthrough
Lets walk through creating a standard definition for a multi node LAMP stack, and we’ll create 2 instances of the entire stack. It will involve 4 machines sharing data and duties.
These interfaces are called capabilities, here’s an example of a SQL one:
Puppet::Type.newtype :sql, :is_capability => true do newparam :name, :is_namevar => true newparam :user newparam :password newparam :host newparam :database end |
This is a generic interface to a database, you can imagine Postgres or MySQL etc can all satisfy this interface, perhaps you could add here a field to confer the type of database, but lets keep it simple. The capability provides a translation layer between 2 unrelated modules.
It’s a pretty big deal conceptually, I can see down the line there be some blessed official capabilities and we’ll see forge modules starting to declare their compatibility. And finally we can get to a world of interchangeable infrastructure modules.
Now I’ll create a defined type to make my database for my LAMP stack app, I’m just going to stick a notify in instead of the actual creating of a database to keep it easy to demo:
define lamp::mysql (
$db_user,
$db_password,
$host = $::hostname,
$database = $name,
) {
notify{"creating mysql db ${database} on ${host} for user ${db_user}": }
} |
I need to tell Puppet this defined type exist to satisfy the producing side of the interface, there’s some new language syntax to do this, it feels kind of out of place not having a logical file to stick this in, I just put it in my lamp/manifests/mysql.pp:
Lamp::Mysql produces Sql {
user => $db_user,
password => $db_password,
host => $host,
database => $database,
} |
Here you can see the mapping from the variables in the defined type to those in the capability above. $db_user feeds into the capability property $user etc.
With this in place if you have a lamp::mysql or one based on some other database, you can always query it’s properties based on the standard user etc, more on that below.
So we have a database, and we want to hook a web app onto it, again for this we use a defined type and again just using notifies to show the data flow:
define lamp::webapp (
$db_user,
$db_password,
$db_host,
$db_name,
$docroot = '/var/www/html'
) {
notify{"creating web app ${name} with db ${db_user}@${db_host}/${db_name}": }
} |
As this is the other end of the translation layer enabled by the capability we tell Puppet that this defined type consumes a Sql capability:
Lamp::Webapp consumes Sql {
db_user => $user,
db_password => $password,
db_host => $host,
db_name => $database,
} |
This tells Puppet to read the value of user from the capability and stick it into db_user of the defined type. Thus we can plumb arbitrary modules found on the forge together with a translation layer between their properties!
So you have a data producer and a data consumer that communicates across a translation layer called a capability.
The final piece of the puzzle that defines our LAMP application stack is again some new language features:
application lamp (
String $db_user,
String $db_password,
Integer $web_instances = 1
) {
lamp::mysql { $name:
db_user => $db_user,
db_password => $db_password,
export => Sql[$name],
}
range(1, $web_instances).each |$instance| {
lamp::webapp {"${name}-${instance}":
consume => Sql[$name],
}
}
} |
Pay particular attention to the application bit and export and consume meta parameters here. This tells the system to feed data from the above created translation layer between these defined types.
You should kind of think of the lamp::mysql and lamp::webapp as node roles, these define what an individual node will do in this stack. If I create this application and set $instances = 10 I will need 1 x database machine and 10 x web machines. You can cohabit some of these roles but I think that’s a anti pattern. And since these are different nodes – as in entirely different machines – the magic here is that the capability based data system will feed these variables from one node to the next without you having to create any specific data on your web instances.
Finally, like a traditional node we now have a site which defines a bunch of nodes and allocate resources to them.
site {
lamp{'app2':
db_user => 'user2',
db_password => 'secr3t',
web_instances => 3,
nodes => {
Node['dev1.example.net'] => Lamp::Mysql['app2'],
Node['dev2.example.net'] => Lamp::Webapp['app2-1'],
Node['dev3.example.net'] => Lamp::Webapp['app2-2'],
Node['dev4.example.net'] => Lamp::Webapp['app2-3']
}
}
lamp{'app1':
db_user => 'user1',
db_password => 's3cret',
web_instances => 3,
nodes => {
Node['dev1.example.net'] => Lamp::Mysql['app1'],
Node['dev2.example.net'] => Lamp::Webapp['app1-1'],
Node['dev3.example.net'] => Lamp::Webapp['app1-2'],
Node['dev4.example.net'] => Lamp::Webapp['app1-3']
}
}
} |
Here we are creating two instances of the LAMP application stack, each with it’s own database and with 3 web servers assigned to the cluster.
You have to be super careful about this stuff, if I tried to put my Mysql for app1 on dev1 and the Mysql for app2 on dev2 this would basically just blow up, it would be a cyclic dependency across the nodes. You generally best avoid sharing nodes across many app stacks or if you do you need to really think this stuff through. It’s a pain.
You now have this giant multi node monolith with order problems not just inter resource but inter node too.
Deployment
Deploying these stacks with the abilities the system provide is pretty low tech. If you take a look at the site above you can infer dependencies. First we have to run dev1.example.net. It will both produce the data needed and install the needed infrastructure, and then we can run all the web nodes in any order or even at the same time.
There’s a problem though, traditionally Puppet runs every 30 minutes and gets a new catalog every 30 minutes. We can’t have these nodes randomly get catalogs in random order since there’s no giant network aware lock/ordering system. So Puppet now has a new model, nodes are supposed to run cached catalogs for ever and only get a new catalog when specifically told so. You tell it to deploy this stack and once deployed Puppet goes into a remediation cycle fixing the stack as it is with an unchanging catalog. If you want to change code, you again have to run this entire stack in this specific order.
This is a nice improvement for release management and knowing your state, but without tooling to manage this process it’s a fail, and today that tooling is embryonic and PE only.
So Choria which I released in Beta yesterday provides at least some relief, it brings a manual orchestrator for these things so you can kick of a app deploy on demand, later maybe some daemon will do this regularly I don’t know yet.
Lets take a look at Choria interacting with the above manifests, lets just show the plan:
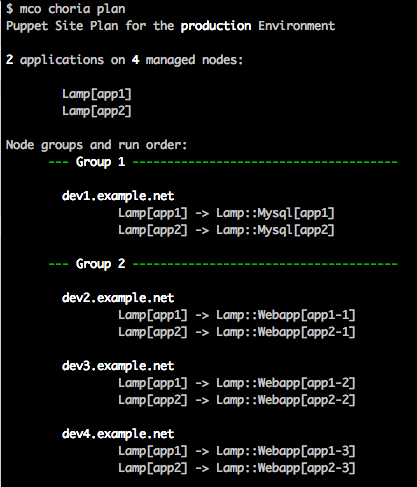
This shows all the defined stacks in your site and group them in terms of what can run in parallel and in what order.
Lets deploy the stack, Choria is used again and it uses MCollective to do the runs using the normal Puppet agent, it tries to avoid humans interfering with a stack deploy by disabling Puppet and enabling Puppet at various stages etc:
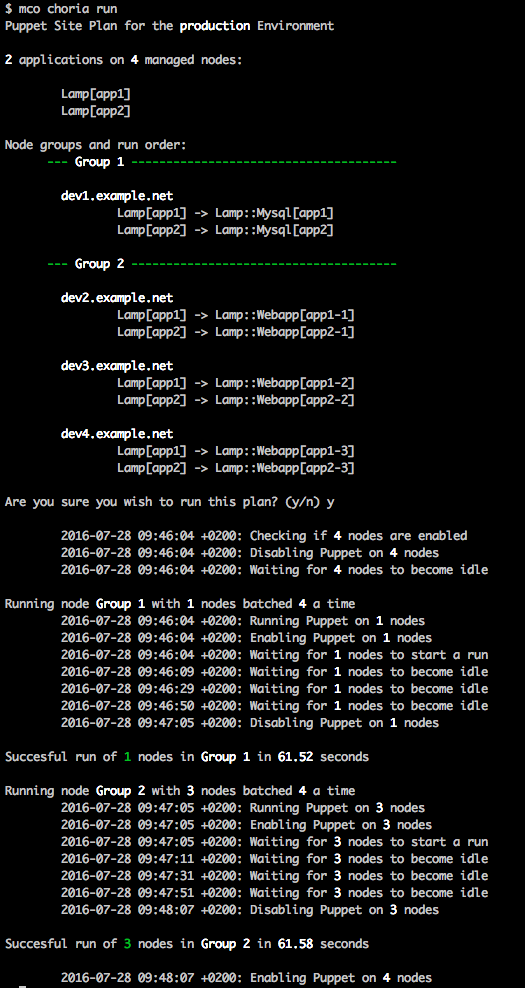
It has options to limit the runs to a certain node batch size so you don’t nuke your entire site at once etc.
Lets look at some of the logs and notifies:
07:46:53 dev1.example.net> puppet-agent[27756]: creating mysql db app2 on dev1 for user user2 07:46:53 dev1.example.net> puppet-agent[27756]: creating mysql db app1 on dev1 for user user1 07:47:57 dev4.example.net> puppet-agent[27607]: creating web app app2-3 with db user2@dev1/app2 07:47:57 dev4.example.net> puppet-agent[27607]: creating web app app1-3 with db user1@dev1/app1 07:47:58 dev2.example.net> puppet-agent[23728]: creating web app app2-1 with db user2@dev1/app2 07:47:58 dev2.example.net> puppet-agent[23728]: creating web app app1-1 with db user1@dev1/app1 07:47:58 dev3.example.net> puppet-agent[23728]: creating web app app2-2 with db user2@dev1/app2 07:47:58 dev3.example.net> puppet-agent[23728]: creating web app app1-2 with db user1@dev1/app1 |
All our data flowed nicely through the capabilities and the stack was built with the right usernames and passwords etc. Timestamps reveal dev{2,3,4} ran concurrently thanks to MCollective.
Conclusion
To be honest, this whole feature feels like a early tech preview and not something that should be shipped. This is basically the plumbing a user friendly feature should be written on and that’s not happened yet. You can see from above it’s super complex – and you even have to write some pure ruby stuff, wow.
If you wanted to figure this out from the docs, forget about it, the docs are a complete mess, I found a guide in the Learning VM which turned out to be the best resource showing a actual complete walk through. This is sadly par for the course with Puppet docs these days 🙁 UPDATE: There is an official sample module here.
There’s some more features here – you can make cross node monitor checks to confirm the DB is actually up before attempting to start the web server for example, interesting. But implementing new checks is just such a chore – I can do it, I doubt your average user will be bothered, just make it so we can run Nagios checks, there’s 1000s of these already written and we all have them and trust them. Tbf, I could probably write a generic nagios checker myself for this, I doubt average user can.
The way nodes depend on each other and are ordered is of course obvious. It should be this way and these are actual dependencies. But at the same time this is stages done large. Stages failed because they make this giant meta dependency layered over your catalog and a failure in any one stage results in skipping entire other, later, stages. They’re a pain in the arse, hard to debug and hard to reason about. This feature implements the exact same model but across nodes. Worse there does not seem to be a way to do cross node notifies of resources. It’s as horrible.
That said though with how this works as a graph across nodes it’s the only actual option. This outcome should have been enough to dissuade the graph approach from even being taken though and something new should have been done, alas. It’s a very constrained system, it demos well but building infrastructure with this is going to be a losing battle.
The site manifest has no data capabilities. You can’t really use hiera/lookup there in any sane way. This is unbelievable, I know there were general lack of caring for external data at Puppet but this is like being back in Puppet 0.22 days before even extlookup existed and about as usable. It’s unbelievable that there’s no features for programatic node assignment to roles for example etc, though given how easy it is to make cycles and impossible scenarios I can see why. I know this is something being worked on though. External data is first class. External data modelling has to inform everything you do. No serious user uses Puppet without external data. It has to be a day 1 concern.
The underlying Puppet Server infrastructure that builds these catalogs is ok, I guess, the catalog is very hard to consume and everyone who want to write a thing to interact with it will have to write some terrible sorting/ordering logic themselves – and probably all have their own set of interesting bugs. Hopefully one day there will be a gem or something, or just a better catalog format. Worse it seems to happily compile and issue cyclic graphs without error, filed a ticket for that.
The biggest problem for me is that this is in the worst place of intersection between PE and OSS Puppet, it is hard/impossible to find out roadmap, or activity on this feature set since it’s all behind private Jira tickets. Sometimes some bubble up and become public, but generally it’s a black hole.
Long story short, I think it’s just best avoided in general until it becomes more mature and more visible what is happening. The technical issues are fine, it’s a new feature that’s basically new R&D, this stuff happens. The softer issues makes it a tough one to consider using.
