This is a follow-up post to other posts I’ve done regarding a new breed of monitoring that I hope to create.
I’ve had some time to think about configuration of monitoring. This is a big pain point in all monitoring systems. Many require you configure all your resources, dependencies etc often in text files. Others have API that you can automate against and the worst ones have only a GUI.
In the modern world where we have configuration management this end up being a lot of duplication, your CM system already knows about inter dependencies etc. Your CM’s facts system could know about contacts for a machine and I am sure we could derive a lot of information from these catalogs. Today bigger sites tend to automate the building of monitor config files using their CM systems but it tends to be slow to adapt to network conditions and it’s quite a lot of work.
I spoke a bit about this in the CMDB session at Puppet Camp so thought I’d lay my thoughts down somewhere proper as I’ve been talking about this already.
I’ve previously blogged about using MCollective for monitoring based on discovery. In that post I pointed out that not all things are appropriate to be monitored using this method as you don’t know what is down. There is an approach to solving this problem though. MCollective supports building databases of what should be there – it’s called Registration. By correlating the discovered information with the registered information you can defer what is absent/unknown or down.
Ideally this is as much configuration as I want to have for monitoring mail queue sizes on all my smart hosts:
scheduler.every '1m' do nrpe("check_mailq", :cf_class => "exim::smarthost") end |
This still leaves a huge problem, I can ask for my a specific service to be monitored on a subset of machines but I cannot defer parent child relationships or know who to notify and this is a huge problem.
Now as I am using Puppet to declare these services and using Puppet based discovery to select which machines to monitor I would like to declare parent child relationships in Puppet even cross-node ones.
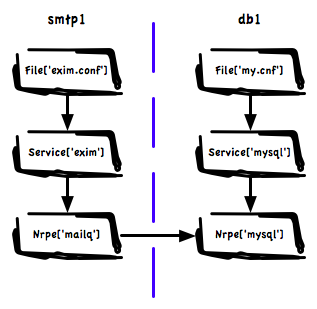 The approach we are currently testing is around loading all my catalogs for all my machines into Neo4J – a purpose built graph database. I am declaring relationships in the manifests and post processing the graph to create the cross node links.
The approach we are currently testing is around loading all my catalogs for all my machines into Neo4J – a purpose built graph database. I am declaring relationships in the manifests and post processing the graph to create the cross node links.
This means we have a huge graph of graphs containing all inter node dependencies. The image shows visually how a small part of this might look. Here we have a Exim service that depends on a database on a different machine because we use a MySQL based Greylisting service.
Using this graph we can answer many questions, among others:
- When doing notifications on a failure in MySQL do not notify about mailq on any of the mail servers
- What other services are affected by a failure on the MySQL Server, if you exposed this to your NOC in a good UI you’ll have to maintain a whole lot less documentation and they know who to call.
- If we are going to do maintenance on the MySQL server what related systems should we schedule downtime on
- What single points of failure exist in the infrastructure
- While planning maintenance on shared resources in big teams with many different groups using databases, find all stake holders
- Create action rule that will shut down all Exim cleanly after failure of the MySQL – mail will spool safely at senders
If we combine this with a rich set of facts we can create a testing framework – perhaps something cucumber based – that let us express infrastructure tests. Platform managers should be able to express baseline design principles the various teams should comply to. These tests are especially important in dynamic environments like ones managed by cloud auto scalers:
- Find all machines with no declared dependencies
- Write a test to check that all shards in a MongoDB cluster has more than 1 member
- Make sure all our MySQL databases are not in the same availability zone
- Find services that depend on each other but that co-habit in the same rack.
- If someone accidentally removes a class from Puppet that manage a DB machine, alert on all failed dependencies that are now unmanaged
And finally we can create automated queries into this database:
- When auto scaling make sure we never end up shutting down machines that would break a dependency
- For an outage on the MySQL server find all related node and their contact information, notify the right people
- When adding nodes using auto scalers make sure we start nodes in different availability zones. If we overlay latency information we can intelligently pick the fastest non-local zone to place a node
The possibilities of pulling in graphs from CM all into one huge queryable data source that understands structure and relationships is really endless. You can see how we have enough information here to derive all the parent child relationships we need for intelligent monitoring.
Ideally Puppet itself would support cross node dependencies but I think that’s some way off. So we have created a hacky solution to declare the relationships now. I think though we need a rich set of relationships. Hard relationships like we have in Puppet now where failure will cause other resources to fail. But we might also have soft relationships that just exist to declare relationships that other systems like monitoring will query.
This is a simple overview of what I have in mind, I expect in the next day or three a follow up post by a co-worker that will show some of the scripts we’ve been working on showing actual queries over this huge graph. We have it working, just polishing things up a bit still.
On a side note, I think one of the biggest design wins in Puppet is that it’s data based. It’s not just a bunch of top-down scripts being run like your old Bash scripts you used to build boxes. Its a directed graph with relationships, that’s queryable and can be used to build other systems, this is a big deal in next generational thinking about systems and I think the above post highlights just a small number of the possibilities this graph brings.
