I’ve been working on rewriting my proof of concept code into actual code I might not feel ashamed to show people, this is quite a slow process so hang in there.
If you’ve been reading my previous posts you’ll know I aim to write a framework for monitoring and event correlation. This is a surprisingly difficult problem space mostly due to the fact that we all have our own ideas of how this should work. I will need to cater literally for all kind of crazy to really be able to call this a framework.
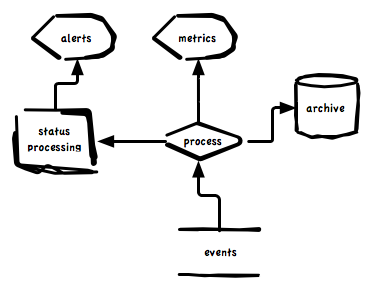 In the most basic form it just take events, archive them, process metrics, process status and raise alerts. Most people will recognize these big parts in their monitoring systems but will also agree there is a lot more to it than this. What describes the extra bits will almost never be answered in a single description as we all have unique needs and ideas.
In the most basic form it just take events, archive them, process metrics, process status and raise alerts. Most people will recognize these big parts in their monitoring systems but will also agree there is a lot more to it than this. What describes the extra bits will almost never be answered in a single description as we all have unique needs and ideas.
The challenge I face is how to make an architecture that can be changed, be malleable to all needs and in effect be composable rather than a prescribed design. These are mostly solved problems in computer science however I do not wish to build a system only usable by comp sci majors. I want to build something that infrastructure developers (read: DevOps) can use to create solutions they need at a speed reaching proof-of-concept velocity while realizing a robust result. These are similar to the goals I had when designing MCollective.
In building the rewrite of the code I opted for this pattern and realized it using middleware and a simple routing system. Routing in middleware is very capable like this post about RabbitMQ describes but this is only part of the problem.
Given the diagram above and given that events can be as simple as a metric for load and as complex as a GitHub commit notify containing sub documents for 100s of commits and can be a mix of metrics, status and archive data we’d want to at least be able to configure these behaviors and 100s like them:
- Only archive a subset of messages
- Only route metrics for certain types of events into Graphite while routing others into OpenTSDB
- Only do status processing on events that has enough information to track state
- Dispatch alerts for server events like load average alerts to a different system than alerts for application level events like payments per hour below a certain threshold. These are often different teams with different escalation procedures.
- Dispatch certain types of metrics to a system that will do alerting based on real time analysis of past trends – this is CPU intensive and you should only subject a subset of events to this processing
- Route a random 10% of the firehose of events into a development environment
- Inject code – in any language – in between 2 existing parts of the event flow and alter the events of route them to a temporary debugging destination.
We really need a routing system that can plug into any part of the architecture and make decisions based on any part of the event.
I’ve created a very simple routing system in my code that plugs all the major components together. Here’s a simple route that sends metrics off to the metric processor. It transforms events that contain metrics into graphite data:
add_route(:name => "graphite", :type => ["metric", "status"]) do |event, routes| routes << "stomp:///queue/events.graphite" unless event.metrics.empty? end |
You can see from the code that we have access to the full event, a sample event is below, and we can make decisions based on any part of the event.
{"name":"puppetmaster",
"eventid":"4d9a33eb2bce3479f50a86e0",
"text":"PROCS OK: 2 processes with command name puppetmasterd",
"metrics":{},"tags":{},
"subject":"monitor2.foo.net",
"origin":"nagios bridge",
"type":"status",
"eventtime":1301951466,
"severity":0} |
This event is of type status and has no metrics so it would not have been routed to the graphite system, while the event below has no status only metrics:
{"name":"um.bridge.nagios",
"created_at":1301940072,
"eventid":"4d9a34462bce3479f50a8839",
"text":"um internal stats for um.bridge.nagios",
"metrics":{"events":49},
"tags":{"version":"0.0.1"},
"subject":"monitor2.foo.net",
"origin":"um stat",
"type":"metric",
"extended_data":{"start_time":1301940072},
"eventtime":1301951558,"severity":0} |
By simply supplying this route:
add_route(:name => "um_status", :type => ["status", "alert"]) do |event, routes| routes << "stomp:///queue/events.status" end |
I can be sure this non status bearing event of type metric wouldn’t reach the status system where it will just waste resources.
You can see the routing system is very simple and sit at the emitting side of every part of the system. If you wanted to inject code between the main Processor and Graphite here simply route the events to your code and then back into graphite when you’re done transforming the events. As long as you can speak to middleware and process JSON you can inject logic into the flow of events.
I hope this will give me a totally composable infrastructure, I think the routes are trivial enough that almost anyone can write and tweak them and since I am using the most simplest of technologies like JSON almost any language can be used to plug into this framework and consume the events. Routes can be put into the system without restarting anything, just drop the files down and touch a trigger file – the routes will immediately become active.
The last example I want to show is the development route I mentioned above that siphons off roughly 10% of the firehose into your dev systems:
add_route(:name => "development", :type => "*") do |event, routes| routes << "stomp:///topic/development.portal" if rand(10) == 1 end |
Here I am picking all event types, I am dumping it into a topic called development.portal but only in roughly 10% of cases. We’re using a topic since they dont buffer or store or consume much memory when the development system is down – events will just be lost when the dev system is down.
I’d simply drop this into /etc/um/routes/portal/development.rb to configure my production portal to emit raw events to my development event portal.
That’s all for today, as mentioned this stuff is old technology and nothing here really solves new problems but I think the simplicity of the routing system and how it allows people without huge amounts of knowledge to re-compose code I wrote in new and interesting ways is quite novel in the sysadmin tool space that’s all too rigid and controlled.
