A short while ago I wrote about releasing a Ruby Development framework for PowerDNS the release is still early days, feature complete but needs some robustness tweaks and a new release will be out in a week or so to address that.
I wanted though to highlight some success that I’ve had using it. I have a small static farm for a client that handles around 2MiB/sec of 200×200 jpg files, this setup is for a startup so out of necessity its all built to be cheap, I host on networks I don’t own yet I need pretty good control over it, what IPs will be used to serve traffic and so forth.
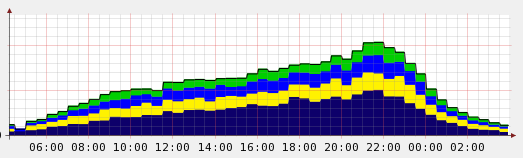
The graph above shows the case before caused by the windows DNS bug, you’ll see the bottom host is working pretty hard getting a large chunk of the bandwidth.
This is a problem because come mid month this poor machine has already used up its allocation of 2.5TiB of transfer and I need to move it from the pool.
So my goal was to shift the traffic to the yellow and green machines and just generally balance things out a bit. I used the Weighted Round Robin feature of ruby-pdns to adjust the biases, it took a bit of fiddling because for some other reason even when this machine gets fewer requests per second it still seems to manage more in terms of bandwidth, this is the eventual code snippet:
ips = ["213.x.x.232", # dark blue "88.x.x.201", # lighter blue "82.x.x.180", # yellow "82.x.x.181"].randomize([1,2,2,3]) # green answer.shuffle false answer.content [:A, ips[0]] answer.content [:A, ips[1]] answer.content [:A, ips[2]] |
The thresholds seems odd but that’s what worked after some fiddling, see the graph below.
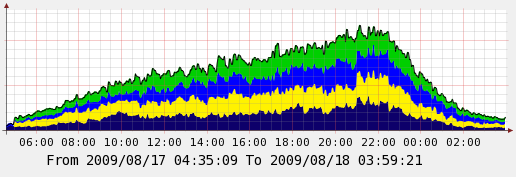
This is much nicer balanced, it’s not perfect and I doubt I will get it perfect with just 4 machines to play with but I believe it’s already at the point where it means I can use all my machines for the entire month without hitting any limits.
Here’s another graph over the week showing things side by side:
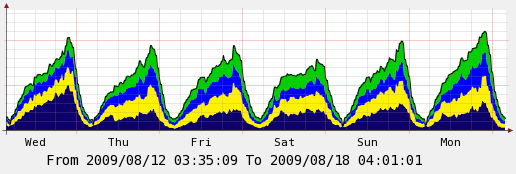
The improvement is very obvious in this graph and you can see I’ve not lost anything in performance between first day and last day on the graph in terms of throughput (the lower days were days where lower traffic is expected).
If I look at my actual transfer used it’s better balanced now, first lets see the 12th:
08/12/09 12.67 GiB | 46.42 GiB | 59.09 GiB | 5.74 Mbit/s 08/12/09 7.71 GiB | 21.32 GiB | 29.04 GiB | 2.82 Mbit/s 08/12/09 9.05 GiB | 23.05 GiB | 32.10 GiB | 3.12 Mbit/s 08/12/09 6.94 GiB | 16.56 GiB | 23.50 GiB | 2.28 Mbit/s |
Again the skew is very clear with a 23GiB on the lowest compared to 59GiB on the highest use machine, on the 17th it looked a lot better:
08/17/09 7.84 GiB | 28.55 GiB | 36.39 GiB | 3.53 Mbit/s 08/17/09 8.46 GiB | 25.66 GiB | 34.12 GiB | 3.31 Mbit/s 08/17/09 11.21 GiB | 30.70 GiB | 41.91 GiB | 4.07 Mbit/s 08/17/09 10.25 GiB | 28.20 GiB | 38.46 GiB | 3.73 Mbit/s |
Obviously much better when looking at the 2nd to last column. The first column is received the increase in those is down to a slightly lower hit ratio on the caching proxy on these machines meaning it’s fetching more files from origin than the others.
Overall I am extremely pleased with this solution, I agree one should not be using DNS as a hammer to all your nails but for startups and cloud based people who do not have control over networks, BGP tables and so forth this really does represent a viable option to what would otherwise be an extremely expensive problem to solve.
