A very typical scenario I come across on many sites is the requirement to monitor something like Puppet across 100s or 1000s of machines.
The typical approaches are to add perhaps a central check on your puppet master or to check using NRPE or NSCA on every node. For this example the option exist to easily check on the master and get one check but that isn’t always easily achievable.
Think for example about monitoring mail queues on all your machines to make sure things like root mail isn’t getting stuck. In those cases you are forced to do per node checks which inevitably result in huge notification storms in the event that your mail server was down and not receiving the mail from the many nodes.
MCollective has had a plugin that can run NRPE commands for a long time, I’ve now added a nagios plugin using this agent to combine results from many hosts.
Sticking with the Puppet example, here are my needs:
- I want to know if anywhere some puppet machine isn’t successfully doing runs.
- I want to be able to do puppetd –disable and not get alerts for those machines.
- I do not want to change any configs when I am adding new machines, it should just work.
- I want the ability to do monitoring on subsets of machines on different probes
This is a pretty painful set of requirements for nagios on its own to achieve. Easy with the help of MCollective.
Ultimately, I just want this:
OK: 42 WARNING: 0 CRITICAL: 0 UNKNOWN: 0 |
Meaning 42 machines – only ones currently enabled – are all running happily.
The NRPE Check
We put the NRPE logic on every node. A simple check command in /etc/nagios/nrpe.d/check_puppet_run.cfg:
command[check_puppet_run]=/usr/lib/nagios/plugins/check_file_age -f /var/lib/puppet/state/state.yaml -w 5400 -c 7200 |
In my case I just want to know there are successful runs happening, if I wanted to know the code is actually compiling correctly I’d monitor the local cache age and size.
Determining if Puppet is enabled or not
Currently this is a bit hacky, I’ve filed tickets with Puppet Labs to improve this. The way to determine if puppet is disabled is to check if the lock file exist and if its 0 bytes. If it’s not zero bytes it means a puppetd is currently doing a run – there will be a pid in it. Or the puppetd crashed and there’s a stale pid preventing other runs.
To automate this and integrate into MCollective I’ve made a fact puppet_enabled. We’ll use this in MCollective discovery to only monitor machines that are enabled. Get this onto all your nodes perhaps using Plugins in Modules.
The MCollective Agent
You want to deploy the MCollective NRPE Agent to all your nodes, once you’ve got it right you can test it easily using something like this:
% mc-nrpe -W puppet_enabled=1 check_puppet_run
* [ ============================================================> ] 47 / 47
Finished processing 47 / 47 hosts in 395.51 ms
OK: 47
WARNING: 0
CRITICAL: 0
UNKNOWN: 0 |
Note we’re restricting the run to only enabled hosts.
Integrating into Nagios
The last step is to add this to nagios. I create SSL certs and a specific client configuration for Nagios and put these in it’s home directory.
The check-mc-nrpe plugin works best with Nagios 3 as it will return subsequent lines of output indicating which machines are in what state so you get the details hidden behind the aggregation in alerts. It also outputs performance data for total node, each status and also how long it took to do the check.
The nagios command would be something like this:
define command{
command_name check_mc_nrpe
command_line /usr/sbin/check-mc-nrpe --config /var/log/nagios/.mcollective/client.cfg -W $ARG1$ $ARG2$
} |
And finally we need to make a service:
define service{
host_name monitor1
service_description mc_puppet-run
use generic-service
check_command check_mc_nrpe!puppet_enabled=1!check_puppet_run
notification_period awakehours
contact_groups sysadmin
} |
Here are a few other command examples I use:
All machines with my Puppet class “pki”, check the age of certs:
check_command check_mc_nrpe!pki!check_pki |
All machines with my Puppet class “bacula::node”, make sure the FD is running:
check_command check_mc_nrpe!bacula::node!check_fd |
…and that they were backed up:
check_command check_mc_nrpe!bacula::node!check_bacula_main |
Using this I removed 100s of checks from my monitoring platform, saving on resources and making sure I can do my critical monitor tasks better.
Depending on the quality of your monitoring system you might even get a graph showing the details hidden behind the aggregation:
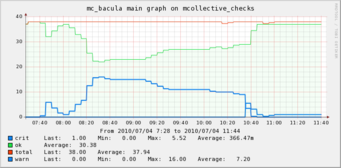
The above is a graph showing a series of servers where the backup ran later than usual, I had 2 alerts only, would have had more than 30 before aggregation.
Restrictions for Probes
The last remaining requirement I had was to be able to do checks on different probes and restrict them. My Collective is one big one spread all over the world which means sometimes things are a bit slow discovery wise.
So I have many nagios servers doing local checks. Using MCollective discovery I can now easily restrict checks, for example If I only wanted to check machines in the USA and I had a fact country I only have to change my command line in the service declaration:
check_command check_mc_nrpe!puppet_enabled=1 country=us!check_puppet_run |
This will then via MCollective discovery just monitor machines in the US.
What to monitor this way
As this style of monitoring is done using Discovery you would need to think carefully about what you monitor this way. It’s totally conceivable that if a node is under high CPU load that it wont respond to discovery commands in time, and so wont get monitored!
You would then for example not want to monitor things like load averages or really critical services this way, but we all have a lot of peripheral things like zombie process counts and a lot of other places where aggregation makes a lot of sense, in those cases by all means consider this approach.
